Linux内核伙伴分配器
当系统内核初始化完毕后,使用页分配器管理物理页,当使用的页分配器是伙伴分配器,伙伴分配器的特点是算法简单且高效。连续的物理页称为页块(page block)。阶(order)是伙伴分配器的专业术语,是页的数量单位,2的n次方个连续页称为n阶页块。满足以下条件的两个n阶页块称为伙伴(buddy --> 英 [ˈbʌdi]):1.两个页块相邻,物理地址连续;2.页块第一页的物理页号是2n的整数倍;3.
当系统内核初始化完毕后,使用页分配器管理物理页,当使用的页分配器是伙伴分配器,伙伴分配器的特点是算法简单且高效。
连续的物理页称为页块(page block)。阶(order)是伙伴分配器的专业术语,是页的数量单位,2的n次方个连续页称为n阶页块。
满足以下条件的两个n阶页块称为伙伴(buddy --> 英 [ˈbʌdi]):
1.两个页块相邻,物理地址连续;
2.页块第一页的物理页号是2n的整数倍;
3.若合并成(n+1)阶页块,第一页的物理页号需是2n+1的整数倍。
伙伴分配器分配和释放物理页的数量单位为阶。分配n阶页块的过程如下:
1.查看是否有空闲的n阶页块,有则直接分配;否则执行下一步;
2.查看是否存在空闲的(n+1)阶页块,若有,将其分裂为两个n阶页块,一个插入空闲n阶页块链表,另一个分配出去;否则执行下一步;
3.查看是否存在空闲的(n+2)阶页块,若有,将其分裂为两个(n+1)阶页块,一个插入空闲(n+1)阶页块链表,另一个再分裂为两个n阶页块,一个插入空闲n阶页块链表,另一个分配出去;若无,继续查看更高阶空闲页块。
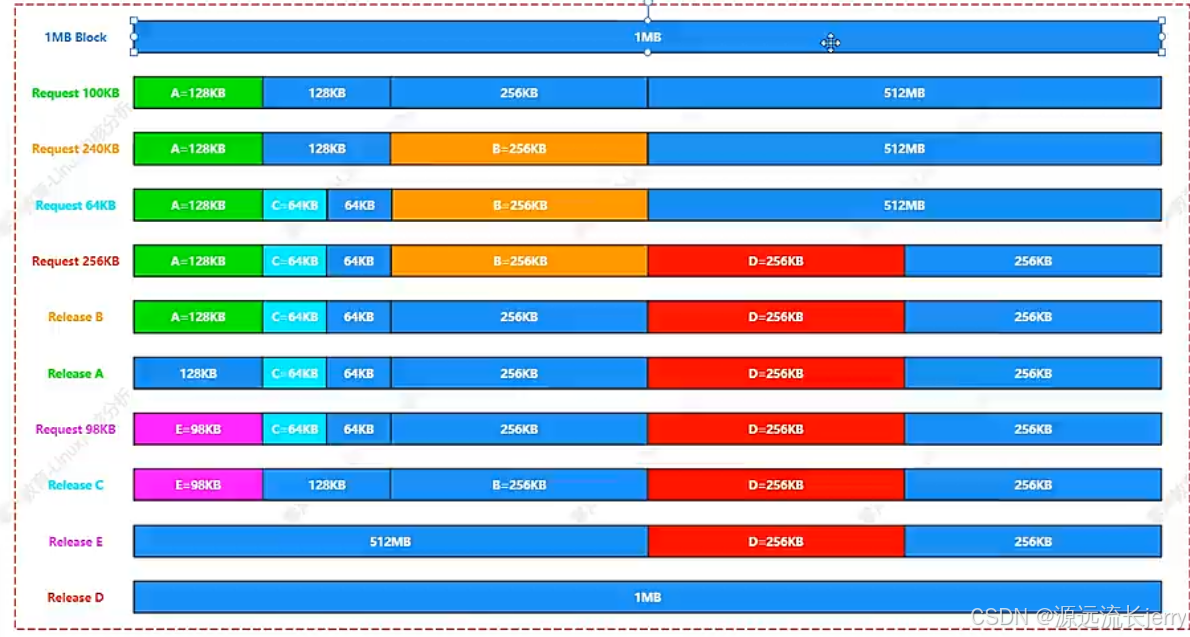
生动图解如下:
1. Request 100KB
- 目标:申请 100KB 内存。
- 操作:
- 100KB 接近 128KB(27字节,对应 7 阶页块)。伙伴分配器查找空闲块,若没有 128KB 块,会向上寻找更大块。
- 找到 1MB 块,分裂为两个 512KB 块;再将其中一个 512KB 分裂为两个 256KB,继续分裂其中一个 256KB 为两个 128KB。最终分配 128KB 块(标记为 A),满足 100KB 需求。
2. Request 240KB
- 目标:申请 240KB 内存。
- 操作:
- 240KB 接近 256KB(28字节,8 阶页块)。分配剩余的 256KB 块(标记为 B),满足 240KB 需求。
3. Request 64KB
- 目标:申请 64KB 内存。
- 操作:
- 64KB 对应 64KB 块(26字节,6 阶)。分配时,找到 128KB 块(A),分裂为两个 64KB 块,分配其中一个(标记为 C)。
4. Request 256KB
- 目标:申请 256KB 内存。
- 操作:
- 剩余空间中找到 512KB 块,分裂为两个 256KB 块,分配其中一个(标记为 D)。
5. Release B(释放 256KB 块)
- 操作:释放 256KB 块 B 时,检查其伙伴是否空闲。此时无相邻伙伴,直接标记为空闲 256KB 块。
6. Release A(释放 128KB 块)
- 操作:释放 128KB 块 A 时,其伙伴(另一个 64KB 块)已被分配(C 还在使用),无法合并,单独标记为空闲 128KB 块。
7. Request 98KB
- 目标:申请 98KB 内存。
- 操作:
- 98KB 接近 128KB。分配空闲的 128KB 块(原 A),标记为 E,满足 98KB 需求。
8. Release C(释放 64KB 块)
- 操作:释放 64KB 块 C 时,其伙伴(另一个 64KB 块,来自 A 的分裂)已空闲,合并为 128KB 块。继续检查 128KB 块的伙伴(若有空闲),最终合并到更大块。
9. Release E(释放 98KB 对应的 128KB 块)
- 操作:释放 128KB 块 E,若其伙伴空闲,逐步向上合并。此时无合适伙伴,标记为空闲 128KB 块。
10. Release D(释放 256KB 块)
- 操作:释放 256KB 块 D 时,若其伙伴(另一个 256KB 块)空闲,合并为 512KB 块;继续检查 512KB 块的伙伴,最终合并为 1MB 块,完成内存回收。
一、分区的伙伴分配器
内核在基本的伙伴分配器基础改进扩展
- 支持内存节点和区域,称为分区的伙伴分配器(zoned buddy allocator);
- 为预防内存碎片,将物理页根据可移动性分组;
- 针对单页分配进行性能优化,为减少处理器间锁竞争,在内存区域增加每处理器页集合。
1.数据结构
分区的伙伴分配器专注于某个内存节点的某个区域。内存区域的结构体zone的成员free_area用来维护空闲页块,数组下标对应页块的阶数,内核源码如下:
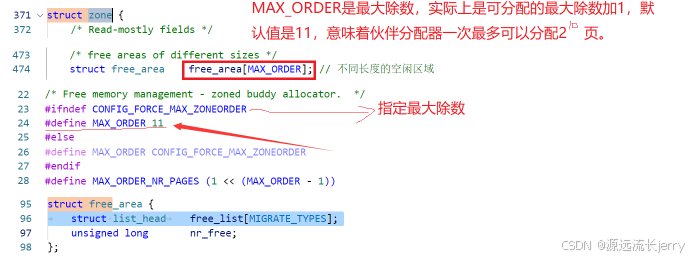
free_area结构体内核源码如下:(其中空闲的 page 结构体通过链表连接在 free_area 的 free_list 中)
2.根据分配标志获取首选区域类型
申请页时,最低的4个标志位用来指定首先得内存区域类型,内核源码如下:

内核使用宏GFP_ZONE_TABLE定义了标志组合到区域类型的映射表,其中GFP_ZONES_SHIFT是区域类型占用的位数,GFP_ZONE_TABLE把每种标志组合映射到 32 位整数的某个位置,偏移是(标志组合 * 区域类型位数),从这个偏移开始的GFP_ZONES_SHIFT个二进制位存放区域类型。
在分区伙伴分配器中,内存被划分为不同区域(如
ZONE_DMA、ZONE_NORMAL等),每种区域有不同特性(如支持硬件 DMA 操作、常规内存等)。上述内容的核心目的是:建立 “分配标志” 与 “内存区域类型” 的映射关系,确保内核申请内存时,能根据分配标志(如是否用于 DMA、是否可移动等)快速定位首选内存区域,使内存分配匹配硬件需求和场景,提升分配效率并避免错误(如让不支持 DMA 的区域处理 DMA 内存请求)。使用方式
设置分配标志:
申请内存时,根据需求设置标志位。例如:
__GFP_DMA:指定内存需从ZONE_DMA区域分配(用于支持 DMA 的硬件);__GFP_MOVABLE:指定分配可移动内存,从适合移动页的区域分配。通过映射表定位区域类型:
内核利用GFP_ZONE_TABLE宏,将标志组合映射到具体区域类型。以标志组合__GFP_DMA为例:
- 根据
GFP_ZONES_SHIFT(区域类型占用位数)计算偏移,从 32 位整数中提取对应区域类型(如ZONE_DMA)。执行内存分配:
分区伙伴分配器根据映射结果,优先从首选区域分配内存。例如,带__GFP_DMA标志的内存申请,会通过映射确定ZONE_DMA为首选区域,分配器从该区域的空闲页块中完成内存分配。【案例示例】
#include <linux/init.h> #include <linux/module.h> #include <linux/gfp.h> MODULE_LICENSE("GPL"); static int __init buddy_allocator_example_init(void) { unsigned long dma_mem_addr; struct page *normal_mem_page; // 1. 设置分配标志,使用__GFP_DMA指定从ZONE_DMA区域分配 gfp_t dma_gfp_mask = __GFP_DMA | GFP_KERNEL; gfp_t normal_gfp_mask = GFP_KERNEL; // 2. 通过映射表定位区域类型并执行内存分配(使用__get_free_pages示例) // 分配ZONE_DMA区域内存,order=0表示分配1页(4KB,假设系统页大小4KB) dma_mem_addr = __get_free_pages(dma_gfp_mask, 0); if (!dma_mem_addr) { pr_info("DMA memory allocation failed\n"); return -ENOMEM; } // 分配常规区域内存(ZONE_NORMAL,默认标志组合映射) normal_mem_page = alloc_pages(normal_gfp_mask, 0); if (!normal_mem_page) { pr_info("Normal memory allocation failed\n"); free_pages(dma_mem_addr, 0); return -ENOMEM; } pr_info("DMA memory allocated at virtual address: %px\n", (void *)dma_mem_addr); pr_info("Normal memory allocated page: %p\n", normal_mem_page); // 3. 内存释放 free_pages(dma_mem_addr, 0); free_pages(normal_mem_page, 0); return 0; } static void __exit buddy_allocator_example_exit(void) { // 模块退出时无需额外操作,内存已在初始化函数释放 } module_init(buddy_allocator_example_init); module_exit(buddy_allocator_example_exit);
3.备用区域列表
如果首选的内存节点或区域不能满足分配请求,可以从备用的内训区域借用物理页。借用必须遵守相应的规则。
一个内存节点的某个区域类型可以从另一个内存节点的相同区域类型借用物理页,比如节点 0 的普通区域可以从节点 1 的普通区域借用物理页;
高区域类型可以从低区域类型借用物理页,比如普通区域可以从 DMA 区域借用物理页;
低区域类型不能从高区域类型借用物理页。比如 DMA 区域不能从普通区域借用物理页。
内存节点的pg_data_t实例已定义备用区域列表,内核源码如下:
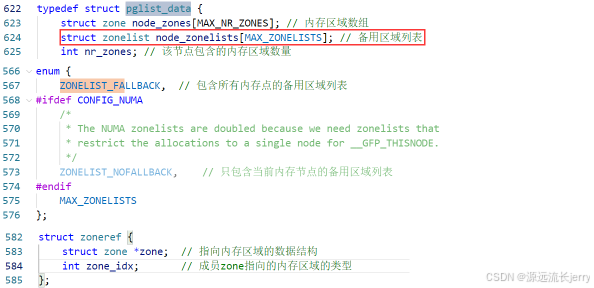
UMA 系统只有一个备用区域列表,按区域类型从高到低排序。假设 UMA 系统包含普通区域和 DMA 区域,那么备用区域列表:(普通区域,DMA 区域)。UMA 系统每个内存节点有两个备用区域列表:一个包含所有内存节点的区域,另一个只包含当前内存节点的区域。
UMA(统一内存访问)架构中,所有处理器对内存的访问延迟一致,内存是全局统一管理的,不存在 NUMA(非统一内存访问)架构下的多内存节点差异。因此,内存区域的备用策略只需基于区域类型(如普通区域、DMA 区域)的优先级统一规划,按区域类型从高到低维护一个备用区域列表,即可满足内存分配时的备用区域查找需求,无需因节点差异额外拆分或复杂处理。
包含所有内存节点的备用区域列表有两种排序方法:
a. 节点优先顺序
先根据节点距离从小到大排序,然后在每个节点里面根据区域类型从高到低排序。优点是优先选择距离近的内存,缺点是在高区域耗尽以前使用低区域。
b. 区域优先顺序
先根据区域类型从高到低排序,然后在每个区域类型里面根据节点距离从小到大排序。优点是减少低区域耗尽的概率,缺点是不能保证优先选择距离近的内存。
默认的排序方法是自动选择最优的排序方法:比如 64 位系统,因需要 DMA 和 DMA32 区域的备用相对少,选择节点优先顺序;如果是 32 位系统,选择区域优先顺序。
4.区域水线
首选的内存区域在什么情况下从备用区域借用物理页呢?每个内存区域有 3 个水线
a. 高水线(high):如果内存区域的空闲页数大于高水线,说明内存区域的内存充足;
b. 低水线(low):如果内存区域的空闲页数小于低水线,说明内存区域的内存轻微不足;
c. 最低水线(min):如果内存区域的空闲页数小于最低水线,说明内存区域的内存严重不足。
数据结构如下:

最低水线以下的内存称为紧急保留内存,在内存严重不足的紧急情况下,给承诺“分给我们少量的紧急保存内存使用,我可以释放更多的内存”的进程使用。
watermark水位控制内核源码重要数据参数:
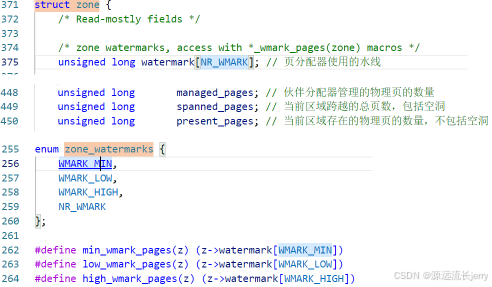
比如HIGH/LOW/MIN三个水位的值是可以计算出来的:
unsigned long managed_pages; // 伙伴分配器管理的物理页的数量
// 代表 zone 中所有的页,包含空洞,计算公式:managed_pages = present_pages - reserved_pages
unsigned long spanned_pages; // 当前区域跨越的总页数,包括空洞
// 代表 zone 中可用的所有物理页,计算公式:spanned_pages - hole_pages
unsigned long present_pages; // 当前区域存在的物理页的数量,不包括空洞
// 代表通过 buddy 管理所有可用的页,计算公式:present_pages - reserved_ + pages
它们三者之间的关系: spanned_pages>present_pages>managed_pages
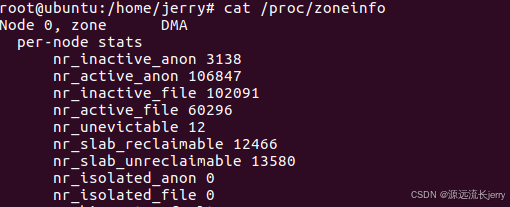
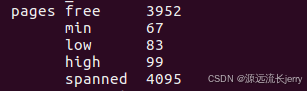
min_free_kbytes代表的是系统保留空闲内存的最低限;watermark[WMARK_MIN]的值是通过min_free_kbytes计算出来的。
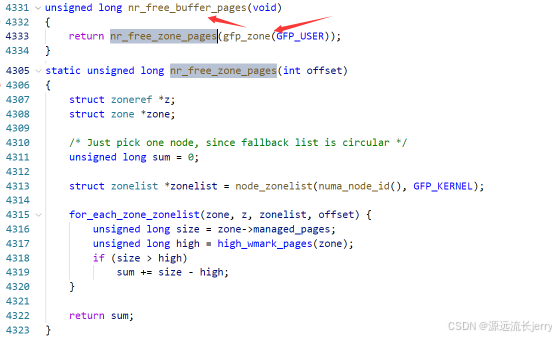
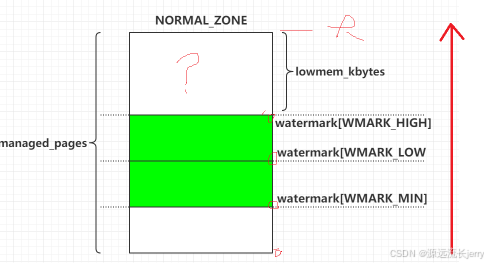
下图展示了 Linux 内存管理中 NORMAL_ZONE(常规内存区域)的内存布局与管理相关参数,具体含义如下:
NORMAL_ZONE:
代表内存管理中的一个常规内存区域,是 Linux 内存管理对物理内存划分的逻辑区域之一,用于管理特定类型的物理页。managed_pages:
图中用范围标识了 “伙伴分配器(Buddy System)” 管理的物理页范围(绿色部分)。这部分内存由伙伴系统负责分配和管理,用于动态内存分配(如进程内存申请)。watermark 水位标记:
- WMARK_HIGH、WMARK_LOW、WMARK_MIN:
这些是内存水位线,用于衡量内存剩余量的阈值:
- WMARK_HIGH:内存高水位,当内存空闲量高于此值时,系统认为内存充足。
- WMARK_LOW:内存低水位,当内存空闲量低于此值时,系统会触发内存回收机制。
- WMARK_MIN:内存最低水位,是内存可用的临界值,确保关键系统功能的内存需求。
lowmem_kbytes:
表示低端内存的总大小(以 KB 为单位),通常指向可直接映射到内核地址空间的物理内存部分,属于 NORMAL_ZONE 的管理范畴。
二、分配页
在Linux内核中,伙伴系统负责以页为单位分配内存,众多页面分配相关函数,如 __alloc_pages_node 、alloc_pages 、__get_free_pages 等 ,最终都会调用 __alloc_pages_nodemask 来实现内存页的分配,它是分区伙伴分配器的核心函数,承担关键的内存分配逻辑。所有分配页的分配器无论是slab分配器还是不连续页分配器都是基于伙伴分配器,因此最终都会调用到__alloc_pages_nodemask,此函数被称为分区伙伴分配器的心脏。函数原型如下:

算法流程:
1、根据分配标志位得到首选区域类型和迁移类型;
2、执行快速路径,使用低水线尝试第一次分配;
3、如果快速路径分配失败,才执行慢速路径。
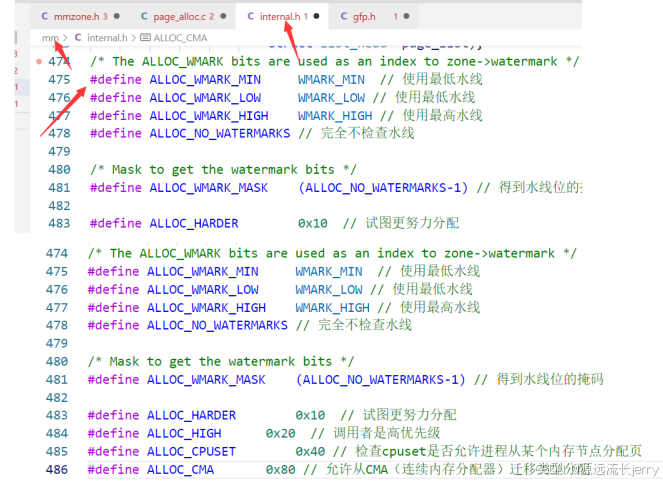
页分配器定义内部分配标志位:
【示例代码】
#include <linux/gfp.h>
#include <linux/mm.h>
#include <linux/init.h>
#include <linux/module.h>
MODULE_AUTHOR("jerry");
MODULE_DESCRIPTION("Allocation Flags Example");
MODULE_LICENSE("GPL");
static int __init my_init(void)
{
struct page *page;
// 使用 ALLOC_WMARK_MIN 标志位,以最低水线尝试分配1个页(order = 0 表示分配1个页)
page = __alloc_pages_nodemask(GFP_KERNEL | ALLOC_WMARK_MIN, 0, NULL, NULL);
if (page) {
// 对分配到的页进行操作,比如获取页的地址等
unsigned long page_address = (unsigned long)page_address(page);
pr_info("Allocated page at address: %lx\n", page_address);
// 用完后释放页
__free_page(page);
} else {
pr_err("Page allocation failed!\n");
}
return 0;
}
static void __exit my_exit(void)
{
pr_info("Module unloaded.\n");
}
module_init(my_init);
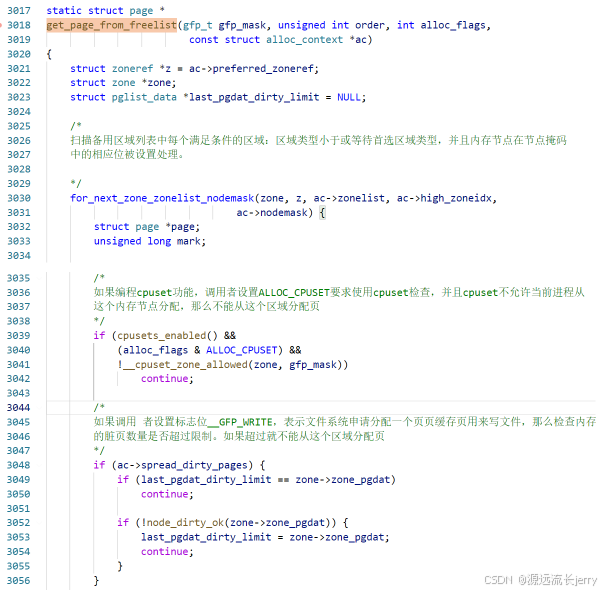
module_exit(my_exit);1.快速路径调用函数如下:

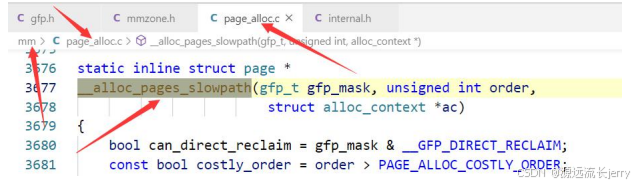
2.慢速路径调用函数如下:
三、释放页
页分配器提供释放页的接口:
void __free_pages (struct page *page, unsigned int order),第一个参数是第一个物理页的 page 实例的地址,第二个参数是阶数。
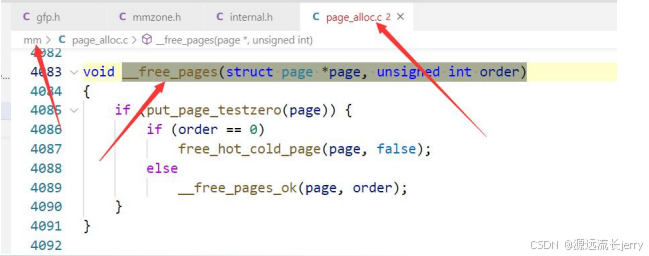
四、具体代码示例
【allocpages_freepages.c】
#include <linux/init.h>
#include <linux/module.h>
#include <linux/gfp.h>
#include <linux/mm_types.h>
#include <linux/mm.h>
// 表示物理内存页的结构体类型(物理内存页直接被组成成一人厚度似于链表的数据结构(即页框链表))
struct page *pages=NULL;
static int __init allocpages_InitFunc(void);
static void __exit allocpages_ExitFunc(void);
static int __init allocpages_InitFunc(void)
{
pages=alloc_pages(GFP_KERNEL,4); // 分配16个物理页面
if(!pages)
{
printk("Prompt:Not enough avilable memory.\n");
// 错误代码,表示没有足够的可用内存
// 返回此错误:意味着系统已经耗尽可用的物理内存或虚拟地址空间
return -ENOMEM;
}
else
{
printk("Prompt:Successfully assigned physical page\n");
printk("Prompt:page_address(page) = 0x%lx\n",(unsigned long)page_address(pages));
}
return 0;
}
static void __exit allocpages_ExitFunc(void)
{
if(pages)
{
// 释放所分配的16个物理页面
__free_pages(pages,4);
printk("Prompt:Successfully released physical page.\n");
}
printk("Prompt:Exit Module.\n");
}
module_init(allocpages_InitFunc); // 内核模块入口函数
module_exit(allocpages_ExitFunc); // 内核模块退出函数
MODULE_LICENSE("GPL"); // 模块的许可证声明
【Makefie】
obj-m:=allocpages_freepages.o
CURRENT_PAHT:=$(shell pwd)
LINUX_KERNEL:=$(shell uname -r)
LINUX_KERNEL_PATH:=/usr/src/linux-headers-$(LINUX_KERNEL)
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PAHT) modules
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PAHT) cleals

2万人民币佣金等你来拿,中德社区发起者X.Lab,联合德国优秀企业对接开发项目,领取项目得佣金!!!
更多推荐



 49
49 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)