告别996!Python网络安全爬虫秘籍,一键搞定情报搜集!
别再以为爬虫只是为了抢火车票啦!在网络安全领域,爬虫可是情报搜集、漏洞挖掘的利器!HTTPURLGETPOSTrobots.txt工欲善其事,必先利其器!requests:发送 HTTP 请求,就像你用浏览器访问网页一样。解析 HTML,帮你从网页中提取信息。lxml:更高效的 HTML 解析器,让你的爬虫跑得更快。pandas:处理和存储数据,让你的战利品井井有条。使用requests有些网站使
告别996!Python网络安全爬虫秘籍,一键搞定情报搜集!
一、网络安全爬虫,到底爬的是啥?(原理篇)
别再以为爬虫只是为了抢火车票啦!在网络安全领域,爬虫可是情报搜集、漏洞挖掘的利器! 简单来说,它就像一只勤劳的小蜜蜂,帮你自动抓取互联网上的各种信息:
- HTTP 请求与响应:
- 想象一下,你用浏览器打开网页,其实就是向服务器发送了一个
HTTP请求。爬虫也是一样,它模拟浏览器的行为,告诉服务器:“嘿,我要这个网页!” - 请求可以指定
URL(网址)、请求方法(GET- 获取信息,POST- 提交信息)、请求头(伪装成浏览器)等等。 - 服务器收到请求后,会返回 HTML 页面、JSON 数据或者其他格式的响应,就像给你送外卖一样。
\2. HTML 解析:
HTML 是网页的骨架,爬虫需要像医生一样“解剖”它,找到我们需要的信息,比如标题、链接、图片、表格等等。
- 想象一下,你用浏览器打开网页,其实就是向服务器发送了一个
- 数据存储:
辛辛苦苦抓来的数据,当然要保存好!可以存到文件里(CSV、JSON),也可以存到数据库里(MySQL、MongoDB),方便后续分析,就像把战利品放进仓库。 - 反爬机制:
- 有些网站不喜欢被爬虫骚扰,会设置一些反爬机制,就像设置了门卫一样。
- 常见的反爬手段包括:User-Agent 检测(检查你是不是伪装的)、频率限制(爬太快就拉黑你)、验证码验证(证明你不是机器人)。
\5. robots.txt 协议:
网站会通过robots.txt文件告诉爬虫:“哪些地方可以爬,哪些地方不能爬”,就像游戏规则一样,爬虫要遵守,不然会被封号!
二、手把手教学:打造你的专属网络安全爬虫(实战篇)
1. 磨刀不误砍柴工:环境准备
工欲善其事,必先利其器!要写爬虫,先安装好必要的库:
pip install requests beautifulsoup4 lxml pandas
-
requests:
发送 HTTP 请求,就像你用浏览器访问网页一样。
-
beautifulsoup4:
解析 HTML,帮你从网页中提取信息。
-
lxml:
更高效的 HTML 解析器,让你的爬虫跑得更快。
-
pandas:
处理和存储数据,让你的战利品井井有条。
2. 代码在手,天下我有:详细代码实现
(1)发送 HTTP 请求 使用 requests 库,模拟浏览器访问网页:
import requests # 定义目标 URL,比如一个漏洞情报网站 url = "https://example.com/vulnerabilities" # 设置请求头,伪装成浏览器访问,防止被识别为爬虫 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36" } # 发送请求 response = requests.get(url, headers=headers) # 检查状态码,200 表示请求成功 if response.status_code == 200: print("请求成功!") print(response.text[:500]) # 打印部分网页内容,看看是不是我们想要的 else: print(f"请求失败,状态码: {response.status_code}")
(2)解析 HTML 数据 使用 BeautifulSoup,提取网页中的关键信息:
from bs4 import BeautifulSoup # 使用 BeautifulSoup 解析 HTML,lxml 解析器更快 soup = BeautifulSoup(response.text, "lxml") # 提取网页标题,看看是不是漏洞情报页面 title = soup.title.string print(f"网页标题: {title}") # 提取所有超链接,可能包含漏洞详情链接 links = [] for a_tag in soup.find_all("a", href=True): links.append(a_tag["href"]) print("提取到的链接:") print(" ".join(links))
(3)存储数据 将提取到的链接保存为 CSV 文件,方便后续分析:
import pandas as pd # 构造数据字典 data = {"Links": links} # 转换为 DataFrame,方便存储 df = pd.DataFrame(data) # 保存为 CSV,index=False 去掉索引列,encoding="utf-8-sig" 解决中文乱码问题 df.to_csv("links.csv", index=False, encoding="utf-8-sig") print("数据已保存到 links.csv")
(4)动态网页处理 有些网站使用 JavaScript 动态加载数据,requests 无法直接抓取。这时需要借助浏览器自动化工具,比如 Selenium 或 Playwright,模拟浏览器行为。
以下是 Selenium 的示例:
pip install selenium
from selenium import webdriver from selenium.webdriver.common.by import By # 配置 Selenium WebDriver(以 Chrome 为例) options = webdriver.ChromeOptions() options.add_argument("--headless") # 无头模式,不显示浏览器界面 driver = webdriver.Chrome(options=options) # 打开网页 driver.get("https://example.com") # 等待页面加载,最多等待 10 秒 driver.implicitly_wait(10) # 提取动态加载的内容,比如漏洞名称 titles = driver.find_elements(By.TAG_NAME, "h1") for title in titles: print(title.text) # 关闭浏览器 driver.quit()
三、反爬虫?不存在的!破解机制大揭秘
遇到反爬虫怎么办?别慌!我们有各种应对策略:
添加随机延迟 像忍者一样,避免频繁请求被发现:
import time import random time.sleep(random.uniform(1, 3)) # 随机延迟 1-3 秒
使用代理 IP 像间谍一样,隐藏你的真实 IP 地址:
proxies = { "http": "http://username:password@proxyserver:port", "https": "http://username:password@proxyserver:port" } response = requests.get(url, headers=headers, proxies=proxies)
处理验证码 遇到验证码?使用 OCR 技术识别它:
pip install pytesseract pillow
from PIL import Image import pytesseract # 读取验证码图片 image = Image.open("captcha.png") # 使用 OCR 识别文本 captcha_text = pytesseract.image_to_string(image) print(f"验证码内容: {captcha_text}")
四、进阶之路:复杂数据,一网打尽
1. JSON:API接口的秘密武器
很多网站的动态内容通过 API 提供 JSON 数据,可以直接请求这些接口,就像拿到藏宝图一样:
api_url = "https://example.com/api/data" response = requests.get(api_url, headers=headers) # 解析 JSON 数据 data = response.json() print(data)
2. 分页:论持久战的重要性
遇到分页数据,要像愚公移山一样,一页一页地抓取:
base_url = "https://example.com/page={}" for page in range(1, 6): url = base_url.format(page) response = requests.get(url, headers=headers) print(f"抓取第 {page} 页内容")
3. 文件下载:把情报搬回家
发现有用的文件?下载到本地慢慢研究:
file_url = "https://example.com/image.jpg" response = requests.get(file_url, stream=True) # 保存到本地 with open("image.jpg", "wb") as file: for chunk in response.iter_content(chunk_size=1024): file.write(chunk) print("文件下载完成!")
五、实战演练:一个完整的网络安全爬虫案例
以下是一个完整的爬虫脚本,抓取新闻网站标题与链接并保存为 CSV 文件,可以用来监控最新的安全漏洞信息:
import requests from bs4 import BeautifulSoup import pandas as pd import time import random # 设置目标 URL 和请求头 base_url = "https://news.ycombinator.com/" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36" } # 存储数据 titles = [] links = [] # 爬取内容 for page in range(1, 4): # 抓取前三页 url = f"{base_url}?p={page}" response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, "lxml") for item in soup.find_all("a", class_="titlelink"): titles.append(item.text) links.append(item["href"]) print(f"完成第 {page} 页爬取") time.sleep(random.uniform(1, 3)) # 随机延迟 # 保存数据到 CSV data = {"Title": titles, "Link": links} df = pd.DataFrame(data) df.to_csv("news.csv", index=False, encoding="utf-8-sig") print("新闻数据已保存到 news.csv")
六、爬虫虽好,可不要贪杯哦!(注意事项)
- 避免法律风险
- 爬取前一定要阅读目标网站的使用条款,遵守游戏规则。
- 严格遵守
robots.txt协议,不要越界。
\2. 优化性能
使用多线程或异步技术(如asyncio、aiohttp)提高效率,就像开了加速器一样。
- 应对反爬
熟练使用代理、延迟和伪装技巧,与反爬虫斗智斗勇。
记住,爬虫是工具,安全第一! 合理利用,才能成为网络安全领域的效率之王!
网络安全工程师(白帽子)企业级学习路线
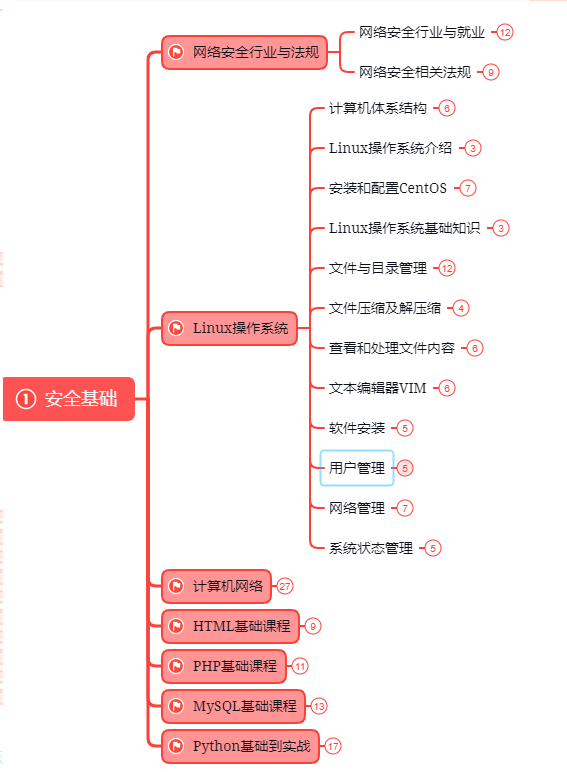
第一阶段:安全基础(入门)
第二阶段:Web渗透(初级网安工程师)

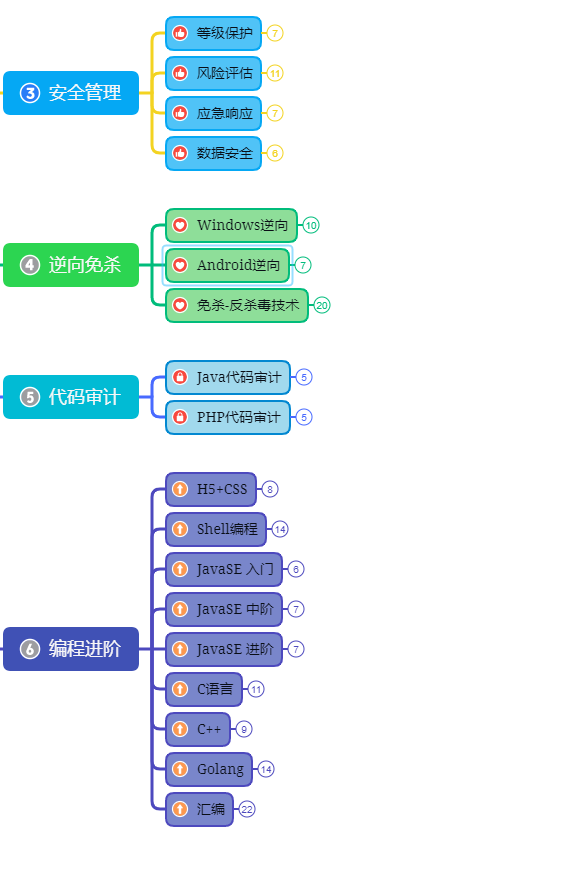
第三阶段:进阶部分(中级网络安全工程师)
如果你对网络安全入门感兴趣,那么你需要的话可以点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!
学习资源分享


2万人民币佣金等你来拿,中德社区发起者X.Lab,联合德国优秀企业对接开发项目,领取项目得佣金!!!
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)