
大模型开发实战篇1:调用DeepSeek的对话接口
很多AI产品对外的接口都复用了OpenAI公司的接口WebAPI,DeepSeek、智谱等也是如此。因此,只要学会OpenAI的接口,其他AI产品也就学调用了。我们就从OpenAI的接口来作为切入点学习。对话接口也是聊天机器人, 在网页上与chatgpt类似的效果。OpenAI的接口是WebAPI形式的Rest API接口,并且还提供了各种常用语言的SDK,比如Python,Java,.Net,J
很多AI产品对外的接口都复用了OpenAI公司的接口WebAPI,DeepSeek、智谱等也是如此。因此,只要学会OpenAI的接口,其他AI产品也就学调用了。我们就从OpenAI的接口来作为切入点学习。
对话接口也是聊天机器人, 在网页上与chatgpt类似的效果。
一、开发环境准备
OpenAI的接口是WebAPI形式的Rest API接口,并且还提供了各种常用语言的SDK,比如Python,Java,.Net,Javascript。这些SDK也同样完全适用于DeepSeek和智谱。大家可以根据自己熟悉的开发语言选择,sdk下载地址:https://platform.openai.com/docs/libraries
本教程以Python作为开发语言。
1、安装Python解释器
官方下载安装包:https://www.python.org/downloads/
安装好后看下版本
命令:python --version
Python 3.13.12、安装Jupyter Lab
JupyterLab是人工智能领域常用的web版本的开发工具,非常好用,优点很多就不一一介绍了。也可以在VSCode,Pycharm 这些IDE开发。
pip install jupyterlab启动Jupyter Lab,可以打开指定的目录,使用以下命令。
jupyter lab二、注册账号
OpenAI的开放平台注册账号有点复杂,需要科学上网。我们可以使用国内的代理平台进行调用。比如我使用的是:aiyi 的,注册地址如下:https://www.apiyi.com/register/?aff_code=LxAQ
注册号后设置令牌key,就可以使用了。DeepSeek的官方的公众平台停止充值,无法调用,也可以使用第3方提供的平台调用,甚至是本地搭建的DeepSeek也同样可以调用,这个后期讲。
三、开发单轮对话接口
1、Python导入常用的包
!pip install tiktoken openai pandas matplotlib plotly scikit-learn numpy我们本次会使用openai包, 若已安装了旧版本,需要更新到最新版本。
pip install --upgrade openai2、对话接口的代码Demo
from openai import OpenAI
client = OpenAI(api_key="填写自己的令牌apikey", base_url="https://vip.apiyi.com/v1")
messages=[
{"role": "system", "content": "你是一个乐于助人的体育界专家。"},
{"role": "user", "content": "2008年奥运会是在哪里举行的?"},
]
data = client.chat.completions.create(
model="gpt-4o-mini",
stream=False,
messages=messages
)
print(data.choices[0].message)(1)我们使用的是aiyi代码,则使用aiyi的令牌key,base_url填写aiyi的接口地址。
(2)调用的接口是 chat.completions对话补齐接口。
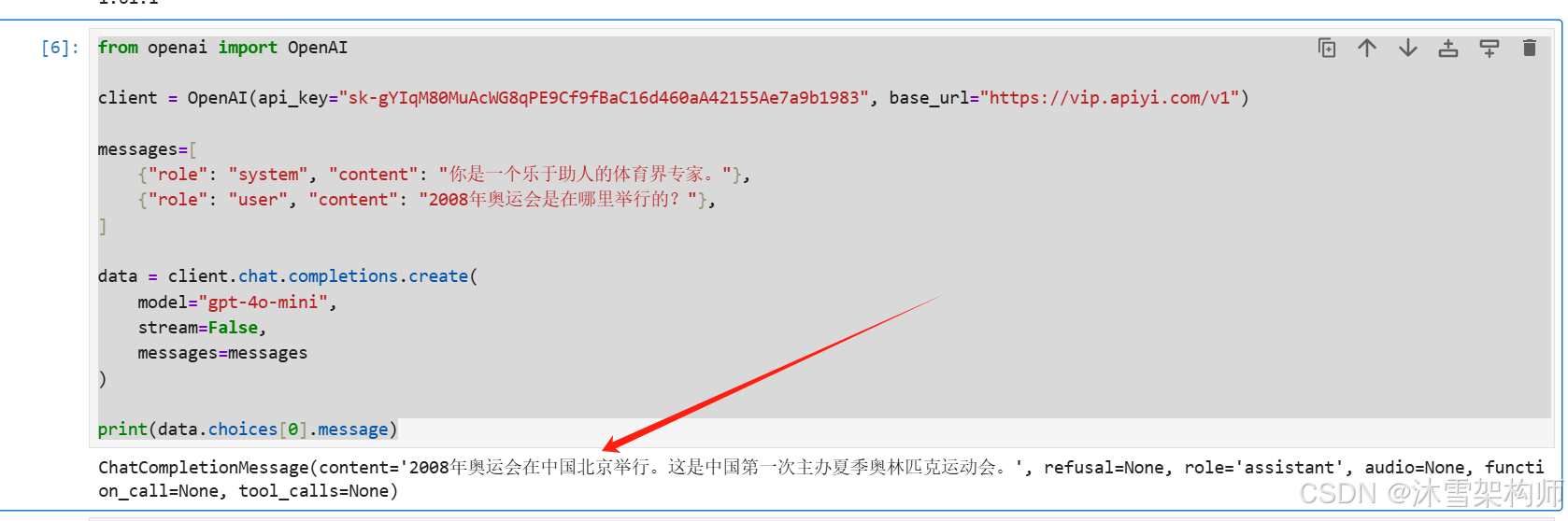
执行会print的结果如上。单轮对话的代码就非常简单。.Net,Java,Javascript语言的开发也是类似的。
也可以print整个返回值data,这里的返回值的格式,在deepseek里稍稍有些不一样,开发的时候注意下。
print(data)
ChatCompletion(id='chatcmpl-89CkHs99ByfRhSd7oB3bz8Cfj5f79', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='2008年奥运会在中国北京举行。这是中国第一次主办夏季奥林匹克运动会。', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None))], created=1739239104, model='gpt-4o-mini', object='chat.completion', service_tier=None, system_fingerprint='fp_5154047bf2', usage=CompletionUsage(completion_tokens=25, prompt_tokens=33, total_tokens=58, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=None, audio_tokens=None, reasoning_tokens=None, rejected_prediction_tokens=None), prompt_tokens_details=PromptTokensDetails(audio_tokens=None, cached_tokens=None)))ChatCompletion(id='chatcmpl-89CkHs99ByfRhSd7oB3bz8Cfj5f79', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='2008年奥运会在中国北京举行。这是中国第一次主办夏季奥林匹克运动会。', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None))], created=1739239104, model='gpt-4o-mini', object='chat.completion', service_tier=None, system_fingerprint='fp_5154047bf2', usage=CompletionUsage(completion_tokens=25, prompt_tokens=33, total_tokens=58, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=None, audio_tokens=None, reasoning_tokens=None, rejected_prediction_tokens=None), prompt_tokens_details=PromptTokensDetails(audio_tokens=None, cached_tokens=None)))
3、请求的接口说明
使用 Chat Completions API 实现对话任务
聊天补全(Chat Completions API)以消息列表作为输入,并返回模型生成的消息作为输出。尽管聊天格式旨在使多轮对话变得简单,但它同样适用于没有任何对话的单轮任务。
主要请求参数说明:
-
model(string,必填)要使用的模型ID。有关哪些模型适用于Chat API的详细信息
-
messages(array,必填)迄今为止描述对话的消息列表
role(string,必填)
发送此消息的角色。
system、user或assistant之一(一般用 user 发送用户问题,system 发送给模型提示信息)。system就是大模型在本次对话中扮演什么角色,比如代码里写的,大模型本次扮演的是“体育专家”,一般使用第3人称“你是xxx专家/教授。。”。-
content(string,必填)消息的内容
-
name(string,选填)此消息的发送者姓名。可以包含 a-z、A-Z、0-9 和下划线,最大长度为 64 个字符
-
stream(boolean,选填,是否按流的方式发送内容)当它设置为 true 时,API 会以 流式SSE( Server Side Event )方式返回内容。SSE 本质上是一个长链接,会持续不断地输出内容直到完成响应。如果不是做实时聊天,默认false即可。
-
max_tokens(integer,选填)在聊天补全中生成的最大 tokens 数。
输入token和生成的token的总长度受模型上下文长度的限制。
-
temperature(number,选填,默认是 1)采样温度,在 0和 2 之间。
较高的值,如0.8会使输出更随机,而较低的值,如0.2会使其更加集中和确定性。
通常建议修改这个(
temperature)或者top_p,但两者不能同时存在,二选一。
四、开发多轮对话接口
单轮对话与多轮对话是完全一样的,只是在messages里将历史对话信息追加上。因为API 是一个“无状态” API,即服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。
沿用上面的单轮对话,进行第2轮对话。
1、将消息追加到 messages 列表中
new_message = data.choices[0].message
new_message_dict = {"role": new_message.role, "content": new_message.content}
# 将消息追加到 messages 列表中
messages.append(new_message_dict)可以看到大模型返回的结果中,role是assistant 小助手,我们直接沿用。
2、第2轮对话
new_chat = {
"role": "user",
"content": "1.讲一个程序员才听得懂的冷笑话;2.今天是几号?3.明天星期几?"
}
messages.append(new_chat)from pprint import pprint
pprint(messages)打印结果
[{'content': '你是一个乐于助人的体育界专家。', 'role': 'system'},
{'content': '2008年奥运会是在哪里举行的?', 'role': 'user'},
{'content': '2008年夏季奥运会在中国的北京举行。', 'role': 'assistant'},
{'content': '1.讲一个程序员才听得懂的冷笑话;2.今天是几号?3.明天星期几?', 'role': 'user'}]data = client.chat.completions.create(
model="gpt-4o-mini",
stream=False,
messages=messages
)
new_message = data.choices[0].message
# 打印 new_messages
print(new_message)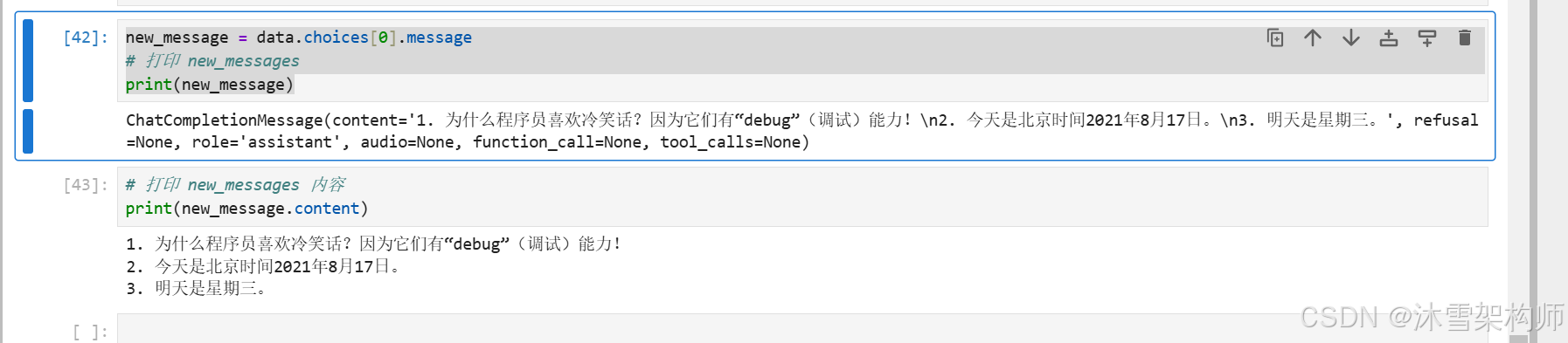
若还有第3轮以及更多轮对话,都要将历史对话带上。
简单的机器人对话接口就讲完了,下一期讲解对话接口的最佳实践。
五、调用本地安装的DeepSeek-R1
1、使用ollama在本地安装deepseek
https://mp.weixin.qq.com/s/jAP3WeKhtXjNO-V6DiyWOQ
本地安装了deepsek-r1:7b,模型名也是这个。
run跑起来
ollama run deepseek-r1:7b2、调用对话接口
from openai import OpenAI
client = OpenAI(api_key="sk-33333", base_url="http://localhost:11434/v1/")
messages=[
{"role": "system", "content": "你是一个乐于助人的体育界专家。"},
{"role": "user", "content": "2008年奥运会是在哪里举行的?"},
]
data = client.chat.completions.create(
model="deepseek-r1:7b",
stream=False,
messages=messages
)
print(data.choices[0].message)(1)api_key随便填写,但必须是英文和数字,不要有中文。
(2)模型model填写deepseek-r1:7b,若你本地安装的参数是别的,就把7b改掉。
(3)base_url是你本地localhost地址。
3、看回答结果
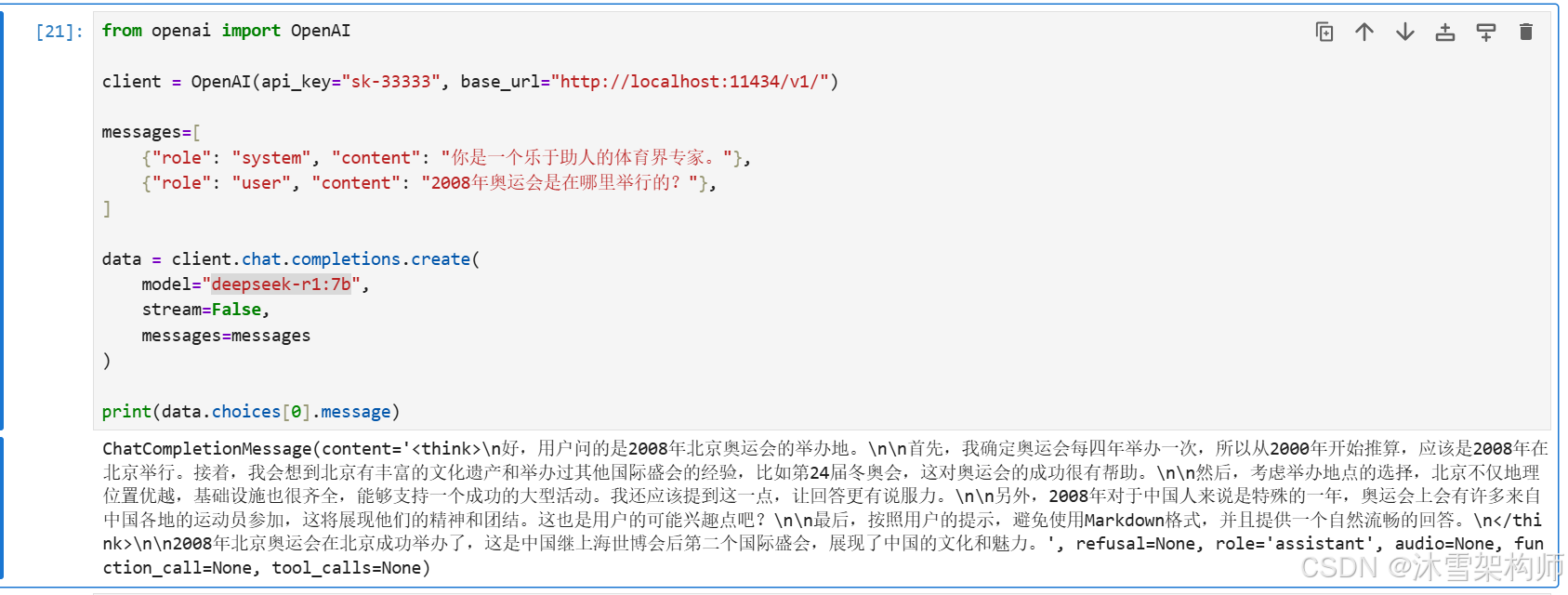
ChatCompletionMessage(content='<think>\n好,用户问的是2008年北京奥运会的举办地。\n\n首先,我确定奥运会每四年举办一次,所以从2000年开始推算,应该是2008年在北京举行。接着,我会想到北京有丰富的文化遗产和举办过其他国际盛会的经验,比如第24届冬奥会,这对奥运会的成功很有帮助。\n\n然后,考虑举办地点的选择,北京不仅地理位置优越,基础设施也很齐全,能够支持一个成功的大型活动。我还应该提到这一点,让回答更有说服力。\n\n另外,2008年对于中国人来说是特殊的一年,奥运会上会有许多来自中国各地的运动员参加,这将展现他们的精神和团结。这也是用户的可能兴趣点吧?\n\n最后,按照用户的提示,避免使用Markdown格式,并且提供一个自然流畅的回答。\n</think>\n\n2008年北京奥运会在北京成功举办了,这是中国继上海世博会后第二个国际盛会,展现了中国的文化和魅力。', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None)
3、调用第3方的deepseek接口
因为deepseek的api接口有很多限制,所以可以使用第3方提供的deepseek接口,比如华为云,腾讯云、硅基流动等,调用方式都一样,仅仅模型名称不一样,接口地址不一样。
我们选择硅基流动: https://cloud.siliconflow.cn/i/M6a0xrcX
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model='deepseek-ai/DeepSeek-V2.5',
messages=[
{'role': 'user',
'content': "中国大模型行业2025年将会迎来哪些机遇和挑战"}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')六、相关文档
OpenAI开发平台的地址
1、设置key以及查询额度
https://platform.openai.com/api-keys
2、WebAPI的帮助文档
https://platform.openai.com/docs/api-reference/making-requests
3、模型介绍
https://platform.openai.com/docs/overview
DeepSeek开发平台的地址
1、快速入门
https://api-docs.deepseek.com/zh-cn/
2、api接口demo演示
https://api-docs.deepseek.com/zh-cn/api/create-completion
3、webapi接口文档
https://api-docs.deepseek.com/zh-cn/guides/multi_round_chat
4、提示词
Prompt Library | DeepSeek API Docs
腾讯云的deepseek
https://cloud.tencent.com/document/product/1772/115969

2万人民币佣金等你来拿,中德社区发起者X.Lab,联合德国优秀企业对接开发项目,领取项目得佣金!!!
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)