Python 爬虫之爬豆瓣TOP250电影 爬虫超详细讲解 零基础入门
先看后赞,养成习惯!!!点赞收藏,人生辉煌!!!讲解我们的爬虫之前,先概述关于爬虫的简单概念(毕竟是零基础教程)爬虫网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。为什么我们要使用爬虫互联网大数据时代,给予我们的是生活的便利以及海量数据爆炸式的出现在网络中。过去
先看后赞,养成习惯!!!
点赞收藏,人生辉煌!!!
讲解我们的爬虫之前,先概述关于爬虫的简单概念(毕竟是零基础教程)
爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
为什么我们要使用爬虫
互联网大数据时代,给予我们的是生活的便利以及海量数据爆炸式的出现在网络中。
过去,我们通过书籍、报纸、电视、广播或许信息,这些信息数量有限,且是经过一定的筛选,信息相对而言比较有效,但是缺点则是信息面太过于狭窄了。不对称的信息传导,以致于我们视野受限,无法了解到更多的信息和知识。
互联网大数据时代,我们突然间,信息获取自由了,我们得到了海量的信息,但是大多数都是无效的垃圾信息。
例如新浪微博,一天产生数亿条的状态更新,而在百度搜索引擎中,随意搜一条——减肥100,000,000条信息。
在如此海量的信息碎片中,我们如何获取对自己有用的信息呢?
答案是筛选!
通过某项技术将相关的内容收集起来,在分析删选才能得到我们真正需要的信息。
这个信息收集分析整合的工作,可应用的范畴非常的广泛,无论是生活服务、出行旅行、金融投资、各类制造业的产品市场需求等等……都能够借助这个技术获取更精准有效的信息加以利用。
网络爬虫技术,虽说有个诡异的名字,让能第一反应是那种软软的蠕动的生物,但它却是一个可以在虚拟世界里,无往不前的利器。
爬虫准备工作
我们平时都说Python爬虫,其实这里可能有个误解,爬虫并不是Python独有的,可以做爬虫的语言有很多例如:PHP,JAVA,C#,C++,Python,选择Python做爬虫是因为Python相对来说比较简单,而且功能比较齐全。
首先我们需要下载python,我下载的是官方最新的版本 PyCharm 2020.3 (Community Edition)
其次我们需要一个运行Python的环境,我用的是pychram
PyCharm: the Python IDE for data science and web development 这个是pycharm的官网
下面根据代码,从下到下给大家讲解分析一遍
-- codeing = utf-8 --,开头的这个是设置编码为utf-8 ,写在开头,防止乱码。
然后下面 import就是导入一些库,做做准备工作,
正则表达式用到 re 库
大体流程分三步走:
基本开发环境
Python 3.9
Pycharm
相关模块的使用
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import xlwt # 进行excel操作
import requests # 网络安装Python并添加到环境变量,pip安装需要的相关模块即可。

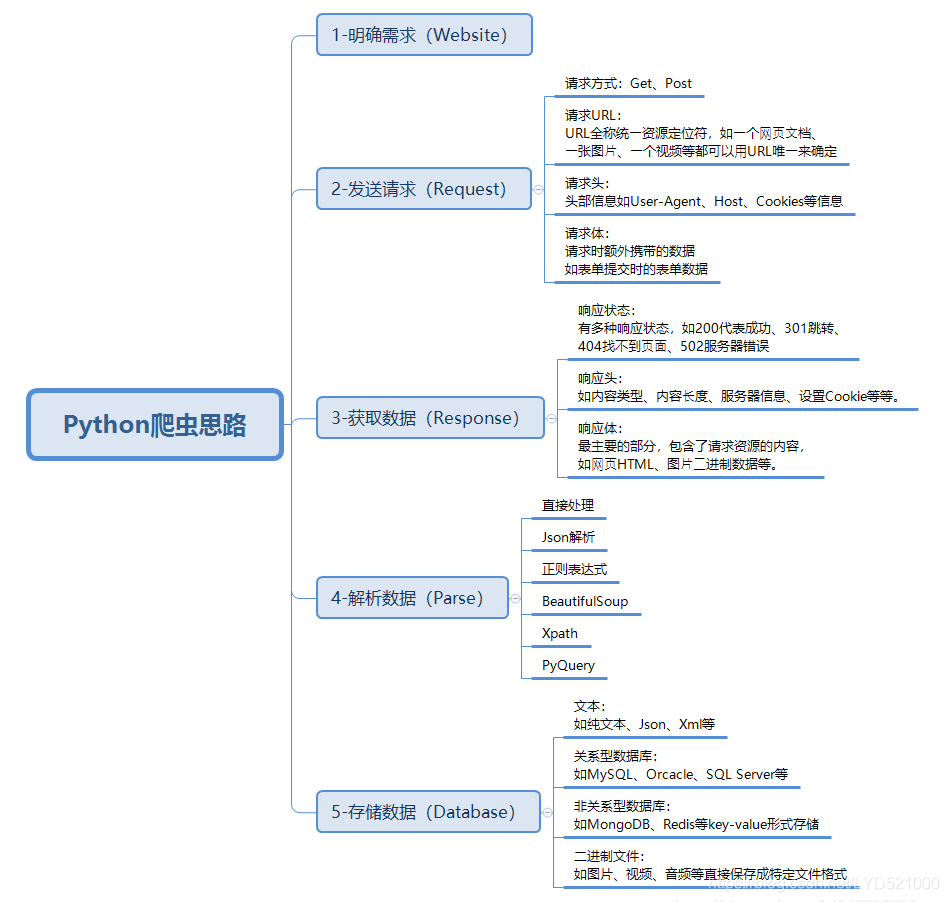
一、明确需求
爬取豆瓣Top250排行电影信息
电影详情
电影图片
电影名字
导演、主演
年份、国家、类型
评分、评价人数
电影简介

二、发送请求
Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模块就是requests。
请求url地址,使用get请求,添加headers请求头,模拟浏览器请求,网页会给你返回response对象
heads = { # 模拟头
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}
#id = i * 25
urls = 'https://movie.douban.com/top250?start=0&filter=' # ID 是网页数据由多少开始 一页有25个 第一个从0开始 总数据250条 因为总共有250条数据,刚开始 就写死,写成0,后面会详细解答
r = requests.get(urls, headers=heads) # GET 获取数据方式这样就可以请求成功了’
这个urls就是用来向网页发送请求用的,那么这里就有老铁问了,为什么这里要写个head呢?
这是因为我们要是不写的话,访问某些网站的时候会被认出来爬虫,显示错误,错误代码
418
这是一个梗大家可以百度下
418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that
the server refuses to brew coffee because it is a teapot. This error
is a reference to Hyper Text Coffee Pot Control Protocol which was an
April Fools’ joke in 1998.三、获取数据
urls = 'https://movie.douban.com/top250?start=0&filter=' # ID 是网页数据由多少开始 一页有25个 第一个从0开始 总数据250条 因为总共有250条数据,刚开始 就写死,写成0,后面会详细解答
r = requests.get(urls, headers=heads) # GET 获取数据方式
print(r.text)heads = { # 模拟头
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}
#id = i * 25
#urls = 'https://movie.douban.com/top250?start=%d&filter=' % id # ID 是网页数据由多少开始 一页有25个 第一个从0开始 总数据250条
urls = 'https://movie.douban.com/top250?start=0&filter= # 因为总共有250条数据,刚开始 就写死,写成0,后面会详细解答
r = requests.get(urls, headers=heads) # GET 获取数据方式
print(r.text)下面是输出结果
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2296266人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
'''四、解析数据
常用解析数据方法: 正则表达式、css选择器、xpath、lxml…
常用解析模块:bs4、parsel…
我经常使用的是 bs4
bs4 是第三方模块,pip install BS4 安装即可
一般爬网页内的内容需要用到正则表达式解析 提前放上来
#=============================正则表达式==================================
#=============================获取网页解析时候用的==========================
detiais = re.compile(r'<a href="(.*?)">') # 详情页正则
banderImage = re.compile(r'<img.*src="(.*?)">', re.S) # 图片正则
conter = re.compile(r'<span class="title">(.*?)</span>') # 名字1
conter1 = re.compile(r'<span class="other">(.*?)</span>') # 名字1
directors = re.compile(r'<p class="">(.*?)</p>', re.S) # 导演
evaluation = re.compile(r'<span>(\d*)人评价</span>') # 评论人数
score = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>') # 评分
probably = re.compile(r'<span class="inq">(.*?)</span>') # 大概什么内容开打豆瓣TOP排行 可以 然后右击第一个 比如我这 肖生克的救赎 点检查 就可以看到下面这东西了

因为所有的电影信息都包含在 li 标签当中。
逐一解析数据
解析数据这里我们用到了 BeautifulSoup(靓汤) 这个库,这个库是几乎是做爬虫必备的库,无论你是什么写法。
下面就开始查找符合我们要求的数据,用BeautifulSoup的方法以及 re 库的
正则表达式去匹配,
for conters in bsou:
temporaryData = [] # 一个临时空数组
webConters = str(conters) # 把网页获取的数据转为 string 类型
#==========================================这里下面就获取到数据了!!!=========================
#==========================================这里用正则表达式 获取解析数据 具体看最上面
#findal
detisiss = detiais.findall(webConters) # 详情
bandersImage = banderImage.findall(webConters) # 图片
# ==========================================电影名字转义 后期优化==================================
movieName = conter.findall(webConters) # 电影名字
moveiEscape = movieName[0].replace(" ", "") # 消除转义
movieName1 = conter1.findall(webConters) # 名字1
moveiEscape1 = movieName1[0].replace("/", "") # 消除转义
#============================================导演名字转义=======================================
directorName = directors.findall(webConters) # 导演
bd = directorName[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
# =============================================================================================
evaluations = evaluation.findall(webConters) # 评论人数
scores = score.findall(webConters) # 评分
probalys = probably.findall(webConters) # 大概什么内容打印结果:
下面的打印结果是因为我放到字典里面了 这样方便看 你也可以
{
'详情': ['https://movie.douban.com/subject/1292052/'],
'图片': ['https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>\n</a>\n</div>\n<div class="info'],
'名字': '肖申克的救赎', '名字1': '\xa0\xa0月黑高飞(港) 刺激1995(台)',
'导演': '\n导演: 弗兰克·德拉邦特 Frank Darabont\xa0\xa0\xa0主演: 蒂姆·罗宾斯 Tim Robbins ...1994\xa0\xa0美国\xa0\xa0犯罪 剧情\n',
'评论人数': ['2298262'],
'评分': ['9.7'],
'大概': ['希望让人自由。']
}这样一条数据就解析出来了,当然 我们获取的数据不是一条,而是250条
这样就嵌套一个for循环,循环10次 一次25条 这就是前面我为什么注释那个URL
heads = { # 模拟头
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}
for i in range(0,10):
id = i * 25
urls = 'https://movie.douban.com/top250?start=%d&filter=' % id # ID 是网页数据由多少开始 一页有25个 第一个从0开始 总数据250条
r = requests.get(urls, headers=heads) # GET 获取数据方式
这样就是可以循环把250条电影都拉出来了五、存储数据
存数据我用的是xls表,一般可以用的还有有sqlite,视自己情况而定
xls表需要支持库 (import xlwt)
第一次先循环8次, 循环8次创建表头
下面 i j
因为是TOP 250 只有250条数据 其实是可以写死的,但是还是没必要
上面不是存了两次数组吗,一次25条 10次就是250条 i相当于循环10次 每次取一次数组出来
输出取出来 在在 j 里面循环 在取出每条数据来
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象
sheet = book.add_sheet('文件夹操作',cell_overwrite_ok=True) # 创建工作表 如果对同一单元格重复操作会发生overwrite Exception,cell_overwrite_ok为可覆盖
col = ("电影详情链接", "图片链接", "影片名", "影片外国名", "导演", "评论人数", "评分", "大概")
for i in range(0, 8):
sheet.write(0, i, col[i]) # 列名 行,列,属性值 (1,1)为B2元素,从0开始计数
for i in range(0,len(array)):
data = array[i]
for j in range(0,8):
sheet.write(i+1, j, data[j]) # 列名 行,列,属性值 (1,1)为B2元素,从0开始计数
book.save(filename_or_stream='豆瓣电影Top250数据.xls') # 保存
print('数据存入成功')![]()
运行会出现这个
打开

OK完成

下面付完整代码
# Pycharm Python on 爬豆瓣TOP250
#
# 爬豆瓣TOP250.py
#
# If you have any questions
#
# please contact me liuliuliuyadong@gmail.com
#
# Create by 果冻 on 2021/3/4
#
# Copyright © 2021 果冻·All rights reserved.
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import xlwt # 进行excel操作
import requests # 网络
#=============================正则表达式==================================
#=============================获取网页解析时候用的==========================
detiais = re.compile(r'<a href="(.*?)">') # 详情页正则
banderImage = re.compile(r'<img.*src="(.*?)">', re.S) # 图片正则
conter = re.compile(r'<span class="title">(.*?)</span>') # 名字1
conter1 = re.compile(r'<span class="other">(.*?)</span>') # 名字1
directors = re.compile(r'<p class="">(.*?)</p>', re.S) # 导演
evaluation = re.compile(r'<span>(\d*)人评价</span>') # 评论人数
score = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>') # 评分
probably = re.compile(r'<span class="inq">(.*?)</span>') # 大概什么内容
totalData = [] #把所有数据放入这个数组
def urlDetails(head):
id = i * 25
urls = 'https://movie.douban.com/top250?start=%d&filter=' % id # ID 是网页数据由多少开始 一页有25个 第一个从0开始 总数据250条
r = requests.get(urls, headers=heads) # GET 获取数据方式
bsou = BeautifulSoup(r.text, 'lxml').find_all('div', class_='item') # 把网页解析为LXML 数据 然后 查找为 <div> class_ = 'item' 里面的数据 因为 它影评详情都在这里div里面
for conters in bsou:
temporaryData = [] # 一个临时空数组
webConters = str(conters) # 把网页获取的数据转为 string 类型
#==========================================这里下面就获取到数据了!!!=========================
#==========================================这里用正则表达式 获取解析数据 具体看最上面
#findal
detisiss = detiais.findall(webConters) # 详情
bandersImage = banderImage.findall(webConters) # 图片
# ==========================================电影名字转义 后期优化==================================
movieName = conter.findall(webConters) # 电影名字
moveiEscape = movieName[0].replace(" ", "") # 消除转义
movieName1 = conter1.findall(webConters) # 名字1
moveiEscape1 = movieName1[0].replace("/", "") # 消除转义
#============================================导演名字转义=======================================
directorName = directors.findall(webConters) # 导演
bd = directorName[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
# =============================================================================================
evaluations = evaluation.findall(webConters) # 评论人数
scores = score.findall(webConters) # 评分
probalys = probably.findall(webConters) # 大概什么内容
#===========================================把数据依次传入空数组===================================
temporaryData.append(detisiss)
temporaryData.append(bandersImage)
temporaryData.append(moveiEscape)
temporaryData.append(moveiEscape1)
temporaryData.append(bd)
temporaryData.append(evaluations)
temporaryData.append(scores)
temporaryData.append(probalys)
totalData.append(temporaryData) # 把临时数据放入数组
#========================================下面这个字典是给自己看的,如果做后台可以传入这个字典进去======
contDic = {'详情': detisiss,
'图片': bandersImage,
'名字': moveiEscape,
'名字1': moveiEscape1,
'导演': bd,
'评论人数': evaluations,
'评分': scores,
'大概': probalys}
dicContDetails(contDic)
saveIntoFile(totalData)
def saveIntoFile(array):
print(len(array))
#========================================下面这个地方开始存入数据======
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象
sheet = book.add_sheet('文件夹操作',cell_overwrite_ok=True) # 创建工作表 如果对同一单元格重复操作会发生overwrite Exception,cell_overwrite_ok为可覆盖
col = ("电影详情链接", "图片链接", "影片名", "影片外国名", "导演", "评论人数", "评分", "大概")
'''
第一次先循环8次, 循环8次创建表头
下面 i j
因为是TOP 250 只有250条数据 其实是可以写死的,但是还是没必要
上面不是存了两次数组吗,一次25条 10次就是250条 i相当于循环10次 每次取一次数组出来
输出取出来 在在 j 里面循环 在取出每条数据来
'''
for i in range(0, 8):
sheet.write(0, i, col[i]) # 列名 行,列,属性值 (1,1)为B2元素,从0开始计数
for i in range(0,len(array)):
data = array[i]
for j in range(0,8):
sheet.write(i+1, j, data[j]) # 列名 行,列,属性值 (1,1)为B2元素,从0开始计数
book.save(filename_or_stream='豆瓣电影Top250数据.xls') # 保存
print('数据存入成功')
def dicContDetails(dic):
'''
传入的电影详情
:param dic: 电影内容
:return:
'''
print(dic)
if __name__ == '__main__':
heads = { # 模拟头
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}
for i in range(0,10):
urlDetails(heads)
print('爬取完毕')
中德AI开发者社区由X.Lab发起,旨在促进中德AI技术交流与合作,汇聚开发者及学者,共同探索前沿AI应用与创新。加入我们,共享资源,共创未来!🚀
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)