针对RAG,优化Amazon Bedrock知识库
处理完成后,评估将提供全面的见解,包括总体指标和每个单项指标的详细性能分解,详细结果中还包含说明性能细微差异的示例对话。对于某些应用来说,0.95的评估分数可能已经足够,这意味着每20个答案中可能有1个答案存在轻微程度的不准确性,但在高风险应用场景中,这一准确度可能是无法接受的。实施全面的版本跟踪系统,不仅要记录所做的更改,还要记录每次调整的背后逻辑、修改前后的性能指标,以及所获得的见解。此外,您

Amazon Bedrock知识库是一项完全托管的服务,能帮助实施从数据摄入到检索以及提示增强的整个检索增强生成(RAG)工作流,且无需构建与数据源的自定义集成与管理数据流。
优化知识库性能的方法并非一成不变:配置参数对每个用例的影响各不相同。因此,重要的是要经常测试并快速迭代,以确定每个用例的最佳配置。
本文将探讨如何评估知识库性能,包括用于评估的指标和数据,以及一些助于改善特定指标的策略与配置更改。
评估知识库性能
RAG是一个复杂的AI系统,结合了多个关键步骤,为了确定影响流程性能的因素,必须对每个步骤进行独立评估。知识库评估框架将评估分解为以下两个阶段:
-
检索:根据查询从文档中检索相关部分,并将检索到的元素作为上下文添加到知识库的最终提示词中。
-
生成:将用户提示词和检索到的上下文发送给大语言模型(LLM),然后将LLM的输出返回给用户。
下图展示了RAG流程中的标准化步骤。
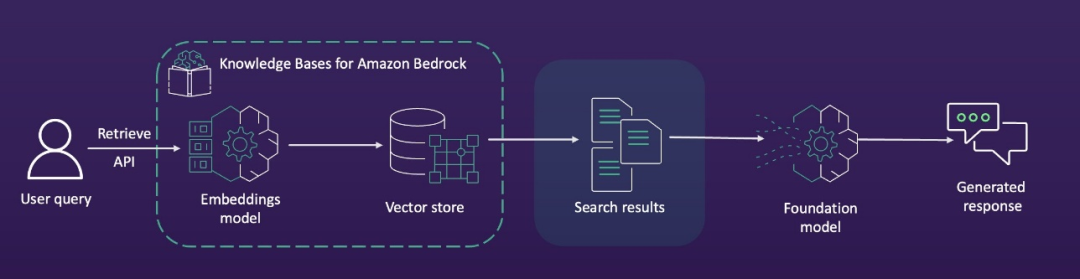
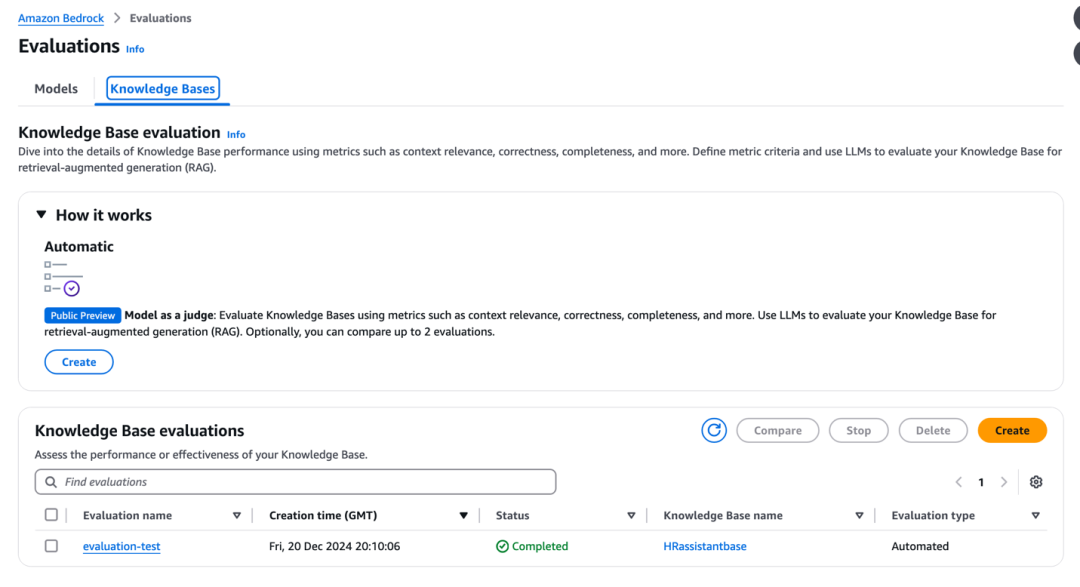
要查看此评估框架的运行情况,请打开Amazon Bedrock控制台,在导航窗格中选择“评估”,然后选择“知识库”选项卡查看评估。
评估检索效果
建议您首先独立评估检索过程,因为这一基础阶段的准确性和质量可能会对RAG工作流中的下游性能指标产生显著影响,可能会引入错误或偏差,并在后续流程阶段中传播。
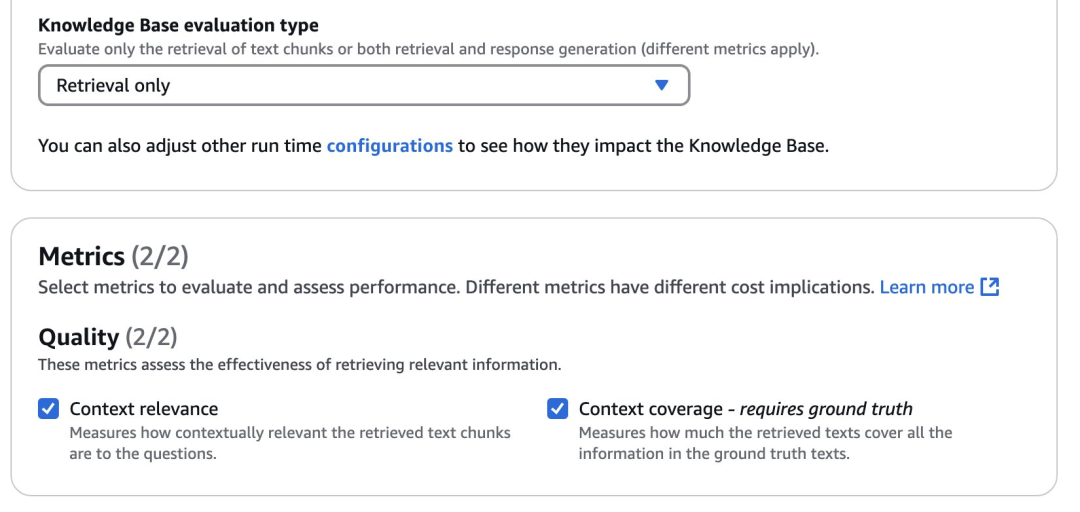
评估检索效果有两个指标:
-
上下文相关性:评估检索到的信息是否直接回应了查询意图,它侧重于检索系统的准确性。
-
上下文覆盖率:衡量检索到的文本在多大程度上覆盖了预期的真实情况。它需要与真实文本进行比较,以评估检索信息的召回率和完整性。
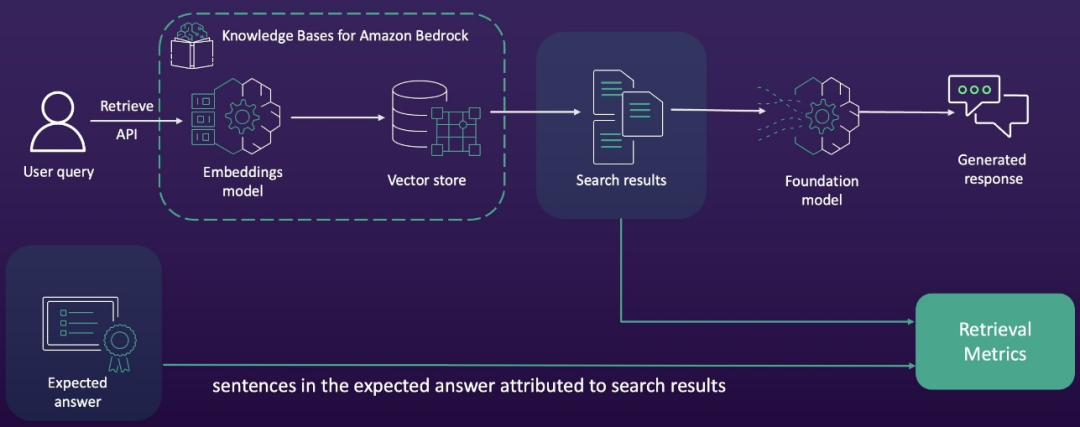
上下文相关性和上下文覆盖率指标,是通过比较RAG流程中的搜索结果与测试数据集中的预期答案而得出的,这一工作流程如下图所示。
运行评估需要您提供一个符合特定格式指南的数据集,该数据集必须采用JSON Lines格式,每行表示一个有效的.json对象。为保持最佳性能,每次评估的数据集最多不超过1000条提示,且数据集中的每个提示都必须是结构良好、有效的.json对象,以便能够被评估系统正确解析和处理。
JSON Lines格式:
https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-evaluation-prompt-retrieve.html
如果您选择评估上下文覆盖率,则需要提供真实文本作为衡量覆盖率的基准。真实文本必须包含referenceContexts,并且真实文本中的每个提示都必须有相应的参考上下文,以便进行准确评估。
以下示例代码展示了所需字段。
{ "conversationTurns": [{ "referenceContexts": [{ "content": [{ "text": "ground truth text" }] }], "prompt": { "content": [{ "text": "query text" }] } }]}左右滑动查看完整示意
有关详细信息,请参阅《为检索评估任务创建提示数据集》。
《为检索评估任务创建提示数据集》
https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-evaluation-prompt-retrieve.html
验证RAG工作流能够成功从向量数据库中检索相关上下文,并且符合预定义的性能标准之后,您可以继续评估流程的生成阶段。Amazon Bedrock评估工具提供了一个全面的评估框架,其中包含8项指标,涵盖响应质量和负责任的AI策略。
响应质量包括以下指标:
-
有用性:评估生成的回答对于解决问题的有用性和全面性。
-
正确性:评估回答是否准确。
-
逻辑连贯性:检查回答中是否存在逻辑漏洞、不一致或矛盾问题。
-
完整性:评估回答是否涵盖了问题的所有方面。
-
忠实性:衡量事实准确性以及抵御虚构内容的能力。
负责任的AI策略包括以下指标:
-
有害性:评估回答中是否存在仇恨、侮辱或暴力内容。
-
刻板印象:评估是否存在对某一群体或个人的偏见性陈述。
-
拒绝回答:衡量系统拒绝回答不适当问题的恰当程度。
响应质量和负责任的AI指标,是通过将RAG流程中的搜索结果和生成的响应与真实答案进行比较而得出的,这一工作流程如下图所示。
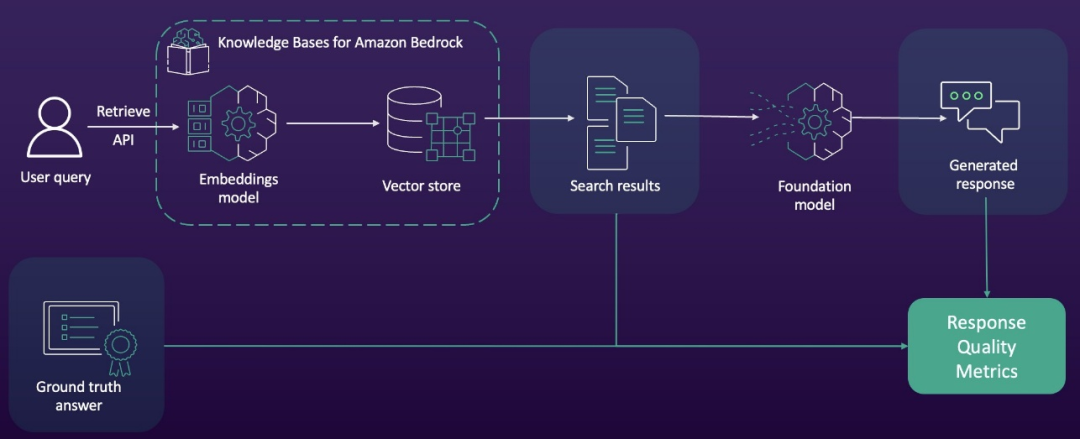
用于评估的数据集必须遵循特定的结构要求,采用JSON Lines格式,且每次评估最多包含1000个提示,每个提示必须是结构清晰、有效的.json对象。在该结构中,有两个关键字段至关重要:prompt字段包含用于模型评估的查询文本,而referenceResponses字段则存储预期的真实响应,模型性能将据此进行衡量。这种格式有助于在不同测试场景中采用标准化、一致性的方法来评估模型输出。
以下示例代码展示了所需字段。
{ "conversationTurns": [{ "referenceResponses": [{ "content": [{ "text": "This is a reference text" }] }],
## your prompt to the model "prompt": { "content": [{ "text": "This is a prompt" }] } }]}左右滑动查看完整示意
有关详细信息,请参阅《为检索和生成评估任务创建提示数据集》。
《为检索和生成评估任务创建提示数据集》
https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-evaluation-prompt-retrieve-generate.html
Amazon Bedrock评估结果示例仪表盘如下图所示。
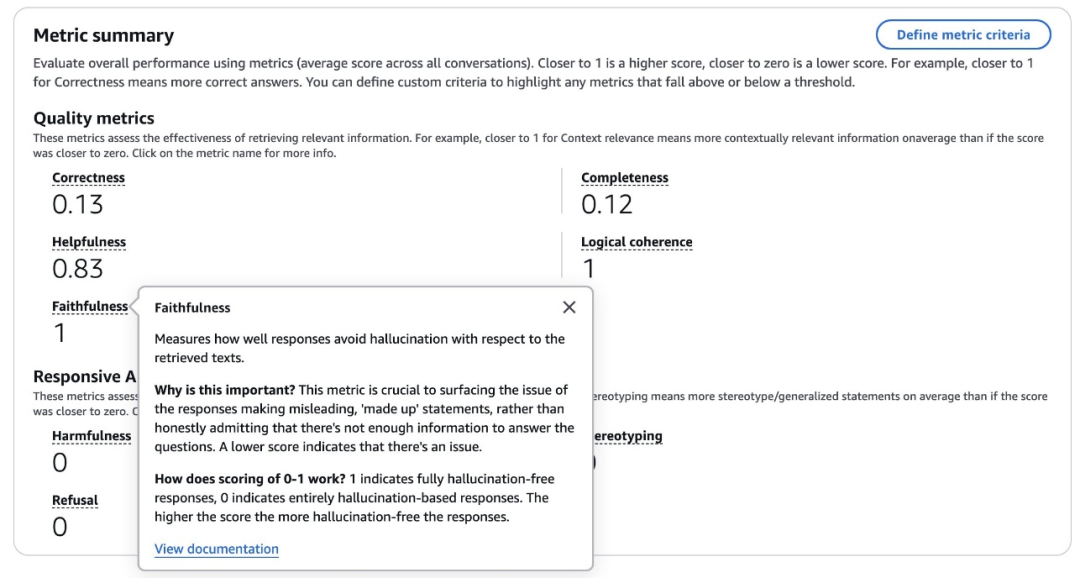
处理完成后,评估将提供全面的见解,包括总体指标和每个单项指标的详细性能分解,详细结果中还包含说明性能细微差异的示例对话。为了获得最大价值,建议进行定性审查,特别是重点审查在任何指标上得分较低的对话。这种深入分析可以帮助您了解导致性能不佳的根本原因,并为改进RAG工作流提供战略性指导。
构建全面测试数据集的策略与要点
创建一个强大的测试数据集对于进行有意义的评估至关重要,下文将继续介绍数据集开发的三种主要方法。
1
人工标注数据收集
人工标注仍然是特定领域高质量数据集的黄金标准,包括以下用途。
-
使用组织的专有文档和答案。
-
使用开源文档集,如Clueweb(百亿级Web文档存储库)。
-
使用专业的数据标注服务,如Amazon SageMaker Ground Truth。
-
使用众包平台,如Amazon Mechanical Turk,进行分布式标注。
Clueweb:
https://arxiv.org/abs/2211.15848
Amazon SageMaker Ground Truth:
https://docs.aws.amazon.com/sagemaker/latest/dg/sms.html
Amazon Mechanical Turk:
https://www.mturk.com/
建议使用人工数据标注来获得特定领域、高质量且细致入微的结果。但使用人工标注生成和维护大型数据集,则耗时耗力且成本高昂。
2
使用大语言模型生成合成数据
合成数据生成提供了一种更自动化、更具成本效益的替代方案,主要有以下两种方法。
1.自指令:
-
使用单一目标模型的迭代过程。
-
模型对查询生成多个响应。
-
提供持续反馈和调整。
2.知识蒸馏:
-
使用多个模型。
-
基于预先存在的模型训练生成响应。
-
通过利用预先训练的模型,实现更快创建数据集。
合成数据生成需要仔细考虑几个关键因素。企业通常必须确保获得最终用户许可协议,并可能需要访问多个LLM。尽管该过程对人工专家验证的需求极低,但这些战略性要求凸显了高效生成合成数据集的复杂性。这种方法为替代传统数据标注方法提供了一种简化方案,并在法律合规与技术创新之间取得了平衡。
3
持续改进数据集:反馈循环策略
开发一种动态、迭代的数据集增强方法,将用户交互转化为宝贵的学习机会。以现有数据为基础,然后实施强大的用户反馈机制,系统捕捉和评估模型在现实世界中的交互情况。建立一个结构化的流程,用于审查和整合被标记的响应,并将每条反馈视为数据集的潜在改进点。
有关在亚马逊云科技服务中实施此类反馈循环的示例,请参阅《Improve LLM performance with human and AI feedback on Amazon SageMaker for Amazon Engineering》。
《Improve LLM performance with human and AI feedback on Amazon SageMaker for Amazon Engineering》
https://aws.amazon.com/blogs/machine-learning/improve-llm-performance-with-human-and-ai-feedback-on-amazon-sagemaker-for-amazon-engineering/
这种方法将数据集开发从一次性的静态工作,转变为活跃的、自适应的系统。通过用户驱动的见解不断扩展和完善数据集,您可以创建一个自我完善机制,逐步提升模型性能和评估指标。数据集的演进不是一个终点,而是一个持续进行的渐进优化之旅。
在开发测试数据集时,应力求达到战略性平衡,准确反映用户将遇到的各种情况。数据集应全面覆盖潜在用例和边缘情况,同时避免不必要的重复。由于每个评估示例都会产生成本,因此应重点关注创建能够最大限度提高见解和性能理解力的数据集,选择能够揭示模型独特行为的示例,而不是冗余的迭代。目标是构建一个有针对性、高效的数据集,既能提供有意义的性能评估,又能避免在多余的测试上浪费资源。
性能提升工具
全面的评估指标不仅仅是性能指标,也还是RAG流程中持续改进的战略路线图。这些指标提供了关键见解,可将抽象的性能数据转化为可操作的智能信息,使您能够做到以下几点。
-
诊断具体的流程薄弱环节。
-
确定改进工作的优先次序。
-
客观评估知识库的准备情况。
-
做出数据驱动的优化决策。
通过系统分析指标,您可以明确回答关键问题:知识库是否足够强大以用于部署?哪些具体组件需要改进?为了获得最大效果,优化工作的重点是什么?
将指标视为一盏诊断明灯,能够照亮从当前性能走向具有卓越可靠性的AI系统的道路。它们不仅仅是衡量的标尺,更是引导的灯塔,为战略性的提升提供了一个清晰、量化的框架。
要实现对RAG流程优化问题的全面深入探讨,这需要撰写一篇详尽的论文才能完成,但本文提供了一个系统性的框架,可在关键维度上实现变革性改进。
数据基础和预处理
数据基础和预处理包含以下最佳实践:
-
对源文档进行清理和预处理,以提高质量、去除噪声、标准化格式以及保持数据一致性。
-
利用相关外部资源扩充训练数据,扩大数据集的多样性和覆盖范围。
-
实施命名实体识别和链接,以改进检索效果、增强语义理解和上下文识别。
-
使用文本摘要技术压缩冗长文档,保留关键信息的同时降低复杂性。
分块策略
考虑以下分块策略:
-
使用语义分块而非固定大小分块,以保留上下文,维护有意义的信息边界。
-
探索不同的分块大小(128~1024个字符),通过智能分段适应语义文本结构并保留意义。有关Amazon Bedrock分块策略的更多详细信息,请参阅知识库内容分块的工作原理。
-
实施带重叠的滑动窗口分块,以减少分块之间的信息损失,通常重叠10%~20%以提供上下文连续性。
-
考虑对长文档使用层次分块,同时捕捉局部和全局上下文的细微差别。
知识库内容分块的工作原理:
https://docs.aws.amazon.com/bedrock/latest/userguide/kb-chunking-parsing.html
嵌入技术
嵌入技术包括以下几种:
-
如果您的文本包含多种语言,您可以尝试使用Cohere Embed(多语言)嵌入模型,这可提高语义理解和检索相关性。
-
尝试不同嵌入维度,以平衡性能和计算效率。
-
实现句子或段落嵌入,超越单词级别的表示。
检索优化
考虑以下检索优化的最佳实践:
-
静态或动态地调整检索到的分块数量,以优化信息密度。在RetrieveAndGenerate(或Retrieve)请求中,进行如下修改。
"retrievalConfiguration": { "vectorSearchConfiguration": { "numberOfResults": NUMBER }}
-
实现元数据过滤,为分块检索添加上下文层次。例如在时间敏感的场景中优先处理最新信息。有关使用Amazon Bedrock知识库进行元数据过滤的代码示例,请参阅GitHub代码库。
-
采用混合搜索,结合密集检索和稀疏检索,融合语义搜索和关键词搜索方法。
-
应用重排模型提高精度,根据相关性重新组织检索到的上下文。
-
尝试不同的相似性度量指标,探索超出标准余弦相似性的其他指标。
-
实施查询扩展技术,转换查询以实现更有效的检索。例如使用查询分解,将复杂查询分解为有针对性的子问题。
元数据过滤:
https://aws.amazon.com/blogs/machine-learning/amazon-bedrock-knowledge-bases-now-supports-metadata-filtering-to-improve-retrieval-accuracy/
GitHub代码库:
https://github.com/aws-samples/amazon-bedrock-samples/blob/main/docs/rag/knowledge-bases/features-examples/03-advanced-concepts/dynamic-metadata-filtering/dynamic-metadata-filtering-KB.md
混合搜索:
https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-hybrid-search/
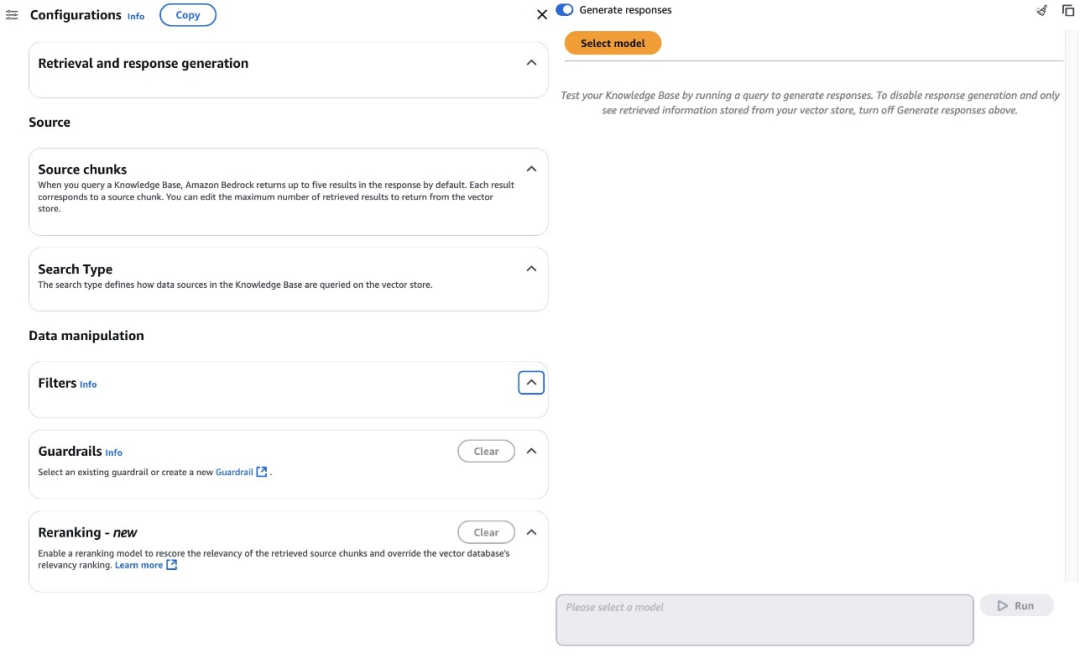
下图展示了Amazon Bedrock控制台上的这些选项。
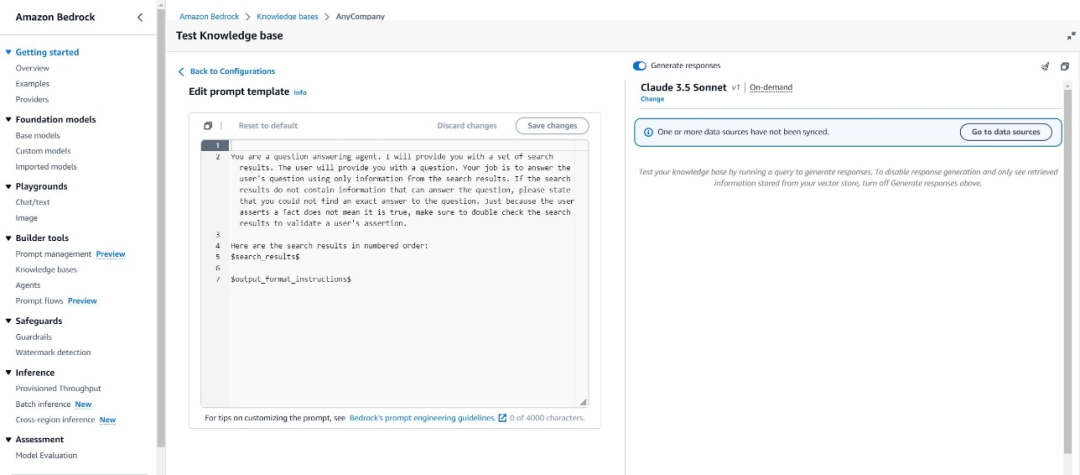
提示词工程
选择模型后,您可以编辑提示模板。
-
设计上下文感知提示,明确指令模型使用检索到的信息。
-
实施少样本提示,使用动态、与查询匹配的示例。
-
根据查询和文档创建动态提示,根据上下文调整指令策略。
-
为检索到的信息提供明确的使用指南,确保生成的响应既忠实又准确。
下图展示了在Amazon Bedrock控制台上编辑提示模板的示例。
模型选择与防护
在选择模型和防护时,请考虑以下因素:
-
根据特定任务要求选择LLM,使模型功能与用例相匹配。
-
基于特定领域数据微调模型,以提升模型在该领域的性能。
-
尝试使用不同规模的模型,平衡性能和计算效率。
-
考虑使用专门的模型配置,例如使用较小模型进行检索,较大模型进行生成。
-
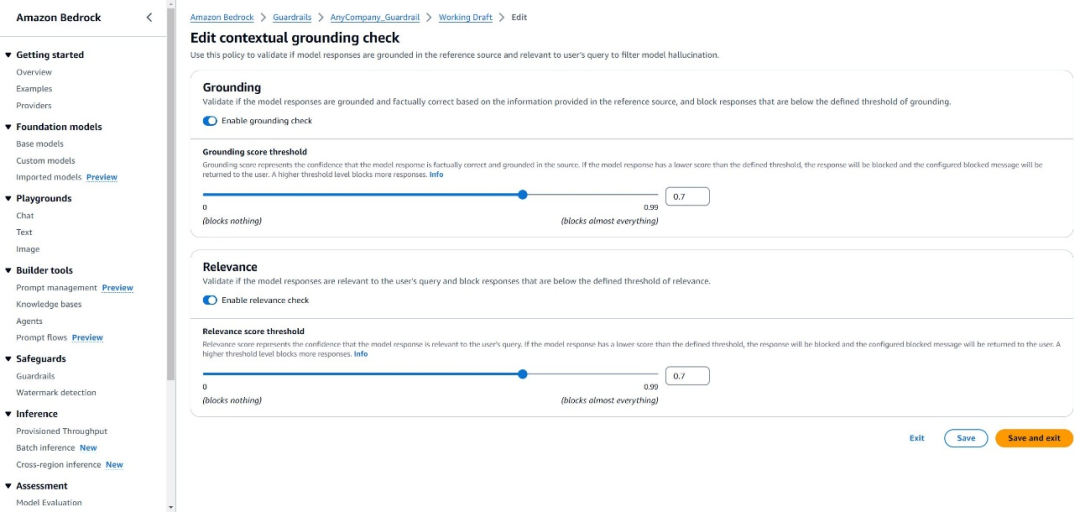
实施上下文一致性检查,确保响应与提供的信息保持一致,如使用Amazon Bedrock Guardrails进行上下文一致性检查(如下图所示)。
-
探索高级搜索范式,例如知识图谱搜索(GraphRAG)。
上下文一致性检查:
https://docs.aws.amazon.com/bedrock/latest/userguide/guardrails-contextual-grounding-check.html
Amazon Bedrock Guardrails:
https://aws.amazon.com/bedrock/guardrails/
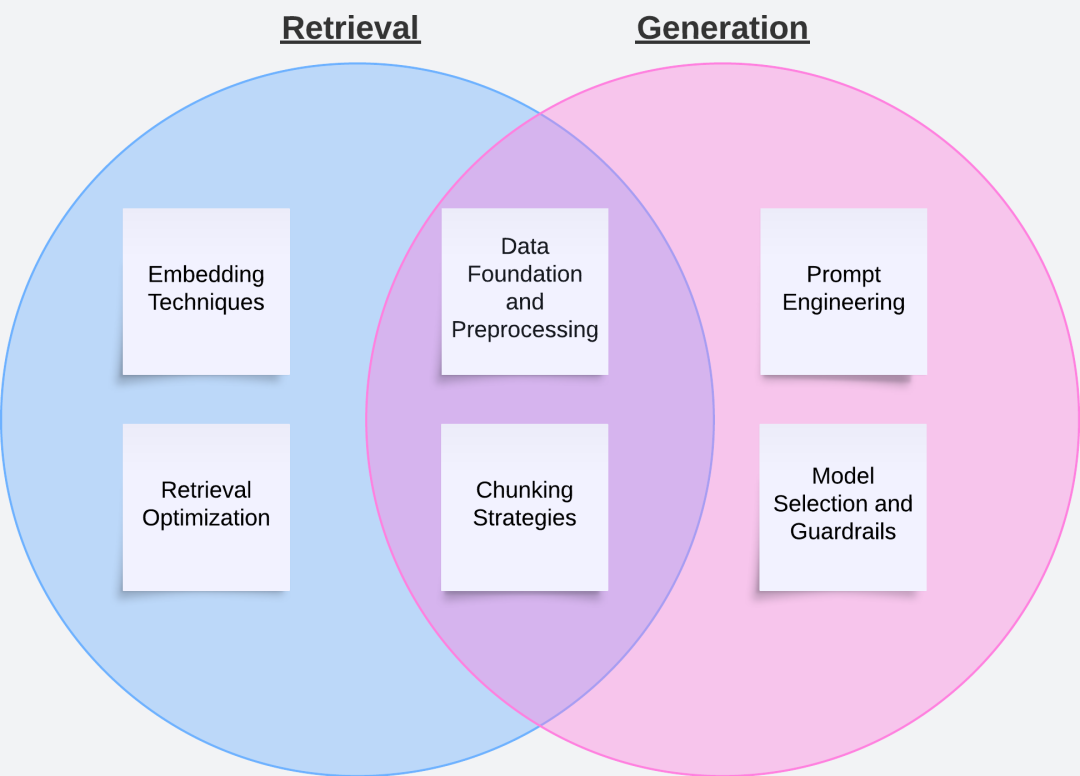
优化知识库路径:关键考量因素
优化RAG系统时,了解性能需求至关重要。可接受的性能标准完全取决于您的应用环境,这包括内部工具、辅助人工工作的系统、面向客户的服务等。对于某些应用来说,0.95的评估分数可能已经足够,这意味着每20个答案中可能有1个答案存在轻微程度的不准确性,但在高风险应用场景中,这一准确度可能是无法接受的。关键在于要根据特定用例对可靠性和精确性的具体需求,来调整优化工作。
另一关键在于要优先完善检索机制,然后再处理生成问题。由于上游性能直接影响下游指标,因此检索优化至关重要。某些技术,尤其是分块策略,会对检索和生成这两个阶段产生细微影响,例如增加分块大小可以通过降低搜索复杂性来提高检索效率,但同时也可能引入无关细节,从而损害生成内容的正确性。这种微妙的平衡需要谨慎、逐步地调整,以确保检索精度和响应质量都能得到系统性提升。
下图展示了上述工具及其与检索、生成和两者之间的关系。
问题诊断
在针对特定性能指标进行优化时,应采取一种细致入微、以人为本的问题诊断方法。将AI系统视为一位同事,其工作内容需要得到深思熟虑且具有建设性的反馈,包括以下步骤。
故障模式识别:
1.系统地映射出表现始终不佳的问题类型。
2.识别导致表现不佳的具体特征,例如:
-
基于列表的查询。
-
专业词汇域。
-
复杂的主题交叉。
3.上下文检索细致分析:
-
进行细粒度的分块相关性分析。
-
量化检索到的无关或不正确的上下文。
-
在检索到的集合中映射精确度分布(例如前15个分块中有5个是相关的,后10个不相关)。
-
了解检索机制的上下文辨别能力。
4.真实值对比分析:
-
将生成的回答与参考答案进行严格比较。
-
诊断潜在的真实值局限性。
-
制定有针对性的改进指导,思考哪些具体指导能提高回答的准确性,以及可能缺失哪些细微的上下文信息。
制定战略性改进策略
面对复杂的RAG流程挑战时,应采用一种有条不紊的战略性策略,将性能优化从一项艰巨任务转变为一个循序渐进的系统性增强过程。
关键在于确定对特定目标指标有直接、可衡量影响的策略,并集中精力于可能带来最高回报的优化点。这意味着要从性能提升的可能性角度出发,仔细分析每一种潜在策略,重点关注能在系统干扰最小的情况下带来显著收益的技术。下图说明了在改进指标时,应优先考虑哪些技术组合。
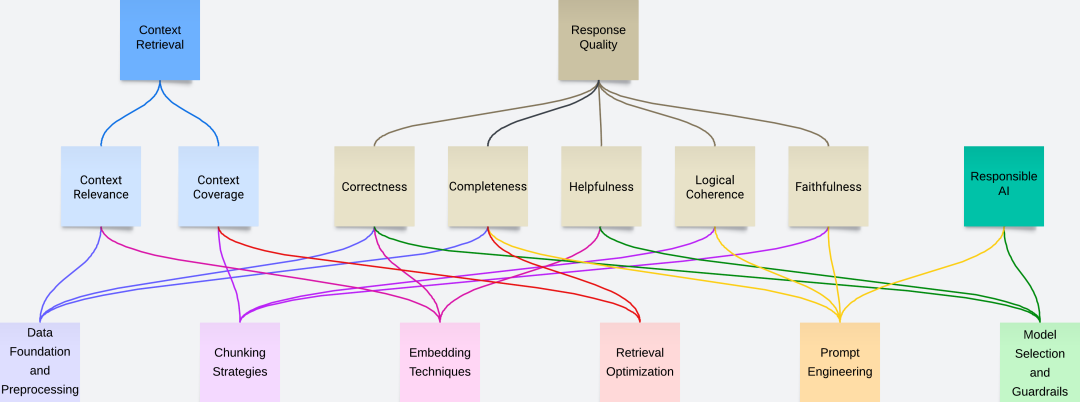
此外,您应优先考虑低阻力的优化策略,例如调整知识库中的可配置参数,或采用对基础设施影响最小的实施方案。除非必要,否则建议您避免重新实施整个向量数据库。
您应该采取精益策略,将RAG流程的改进变成一个有条不紊的持续改进过程。采用战略性循序渐进的原则:进行有目的、有针对性的调整,这些调整既要足够细微,以便精确衡量,同时又要足够重要,能够推动性能提升。
每一次修改都是一次实验性干预,都要经过严格测试,以了解其具体影响。实施全面的版本跟踪系统,不仅要记录所做的更改,还要记录每次调整的背后逻辑、修改前后的性能指标,以及所获得的见解。
最后,在评估性能时,应采用一种全面且富有同理心的方法,这种方法超越了单纯的量化指标。而是将评估过程视为一场促进成长和理解的合作对话,正如同您在指导一位才华横溢的团队成员时所采取的细致方式。不要仅仅将性能简化为冰冷的数字指标,而是要深入挖掘其背后的动因、情境挑战以及发展潜力。有意义的评估不仅超越了表面层次的衡量,更需要对能力、局限性以及性能的独特情境有深刻洞察。
总结
针对RAG优化Amazon Bedrock知识库是一个需要进行系统测试和改进的迭代过程。成功源于有条不紊地使用提示词工程和分块等技术,来改进RAG的检索和生成阶段。通过跟踪整个过程中的关键指标,您可以衡量优化措施的影响,并确保它们满足应用程序的要求。
有关优化Amazon Bedrock知识库的更多信息,请参阅指南《如何评估Amazon Bedrock资源的性能》。
《如何评估Amazon Bedrock资源的性能》
https://docs.aws.amazon.com/bedrock/latest/userguide/evaluation.html
本篇作者

Clement Perrot
亚马逊云科技高级解决方案架构师和人工智能与机器学习专家,他帮助初创企业利用亚马逊云科技服务构建和使用人工智能。

Miriam Lebowitz
亚马逊云科技解决方案架构师,专注于为初创企业提供支持。她利用自己在人工智能与机器学习领域的经验,指导客户选择并实施适合其业务目标的技术,帮助其在竞争激烈的初创企业世界中实现可扩展的增长和创新。

Clement Perrot
亚马逊云科技解决方案架构师和人工智能与机器学习(AI/ML)专家。她通过推荐合适的亚马逊云科技解决方案,帮助企业客户解决业务问题。她在信息技术领域拥有24年以上的经验,能够帮助客户在亚马逊云科技云制定战略、开发业务并解决业务现代化问题。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!

中德AI开发者社区由X.Lab发起,旨在促进中德AI技术交流与合作,汇聚开发者及学者,共同探索前沿AI应用与创新。加入我们,共享资源,共创未来!🚀
更多推荐



 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)